Understand Code Layout
Use this document as a quick start guide to begin developing in OpenMetadata. Below, we address the following topics:- Schema (Metadata Models)
- APIs
- System and Components
Schema (Metadata Models)
OpenMetadata takes a schema-first approach to model metadata. We define entities, types, API requests, and relationships between entities. We define the OpenMetadata schema using the JSON Schema vocabulary. We convert models defined using JSON Schema to Plain Old Java Objects (POJOs) using thejsonschema2pojo-maven-plugin plugin as defined in pom.xml. You can find the generated POJOs under OpenMetadata/openmetadata-service/target/generated-sources/jsonschema2pojo.
Entities
You can locate defined entities in the directoryOpenMetadata/openmetadata-spec/src/main/resources/json/schema/entity. Currently, OpenMetadata supports the following entities:
- data
- feed
- policies
- services
- tags
- teams
Types
All OpenMetadata supported types are defined underOpenMetadata/openmetadata-spec/src/main/resources/json/schema/type.
API request objects
The API request objects are defined underOpenMetadata/openmetadata-spec/src/main/resources/json/schema/api.
API
OpenMetadata uses the Dropwizard Java framework to build REST APIs. You can locate defined APIs in the directoryOpenMetadata/openmetadata-service/src/main/java/org/openmetadata/service/resources. OpenMetadata uses Swagger to generate API documentation following OpenAPI standards.
System and Components
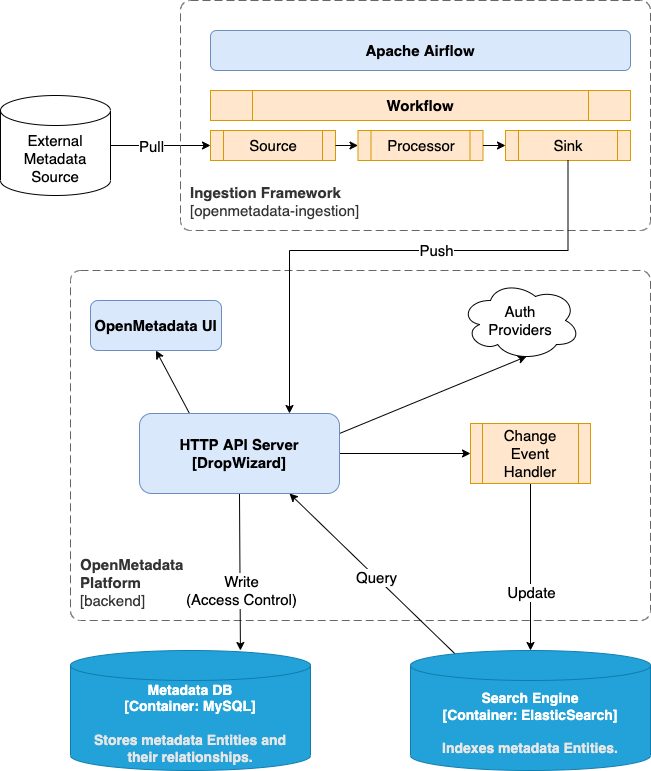
Events
OpenMetadata captures changes to entities asevents and stores them in the OpenMetadata server database. OpenMetadata also indexes change events in Elasticsearch to make them searchable.
The event handlers are defined under OpenMetadata/openmetadata-service/src/main/java/org/openmetadata/service/events and are applied globally to any outgoing response using the ContainerResponseFilter.
Database
OpenMetadata uses MySQL or Postgres for the metadata catalog. The catalog code is located in the directoryOpenMetadata/openmetadata-service/src/main/java/org/openmetadata/service/jdbi3.
The database entity tables are created with the script OpenMetadata/bootstrap/openmetadata-ops.sh. Flyway is used for managing the database table versions.
Elasticsearch
OpenMetadata uses Elasticsearch to store the Entity change events and makes it searchable by search index. TheOpenMetadata/openmetadata-service/src/main/java/org/openmetadata/service/elasticsearch/ElasticSearchEventPublisher.java is responsible for capturing the change events and updating Elasticsearch.
Elasticsearch indices are created when the OpenMetadata/ingestion/pipelines/metadata_to_es.json ingestion connector is run.
Authentication/Authorization
OpenMetadata uses Google OAuth for authentication. All incoming requests are filtered by validating the JWT token using the Google OAuth provider. Access control is provided byAuthorizer.
See the configuration file OpenMetadata /conf/openmetadata.yaml for the authentication and authorization configurations.
Ingestion
Ingestion is a simple Python framework to ingest metadata from external sources into OpenMetadata. Connectors OpenMetadata defines and uses a set of components calledConnectors for metadata ingestion. Each data service requires its own connector. See the documentation on how to build a connector for details on developing connectors for new services.
Workflow is a simple orchestration job that runs Source, Processor, Sink, Stage and BulkSink based on the configurations present under OpenMetadata/ingestion/examples/workflows.
There are some popular connectors already developed and can be found under:
- Source →
OpenMetadata/ingestion/src/metadata/ingestion/source - Processor →
OpenMetadata/ingestion/src/metadata/ingestion/processor - Sink →
OpenMetadata/ingestion/src/metadata/ingestion/sink - Stage →
OpenMetadata/ingestion/src/metadata/ingestion/stage - BulkSink →
OpenMetadata/ingestion/src/metadata/ingestion/bulksink
OpenMetadata/ingestion/examples/airflow/dags for reference DAG definitions.
JsonSchema python typings
You can generate Python types for OpenMetadata models defined using Json Schema using the make generate command of the Makefile. Generated files are located in the directory OpenMetadata/ingestion/src/metadata/generated