{icon &&
 }
}
{name}
{stage}Feature List
{totalAvailableFeatures.map(feature =>
✓ {feature}
)}
{unavailableFeatures.map(feature =>
✕ {feature}
)}
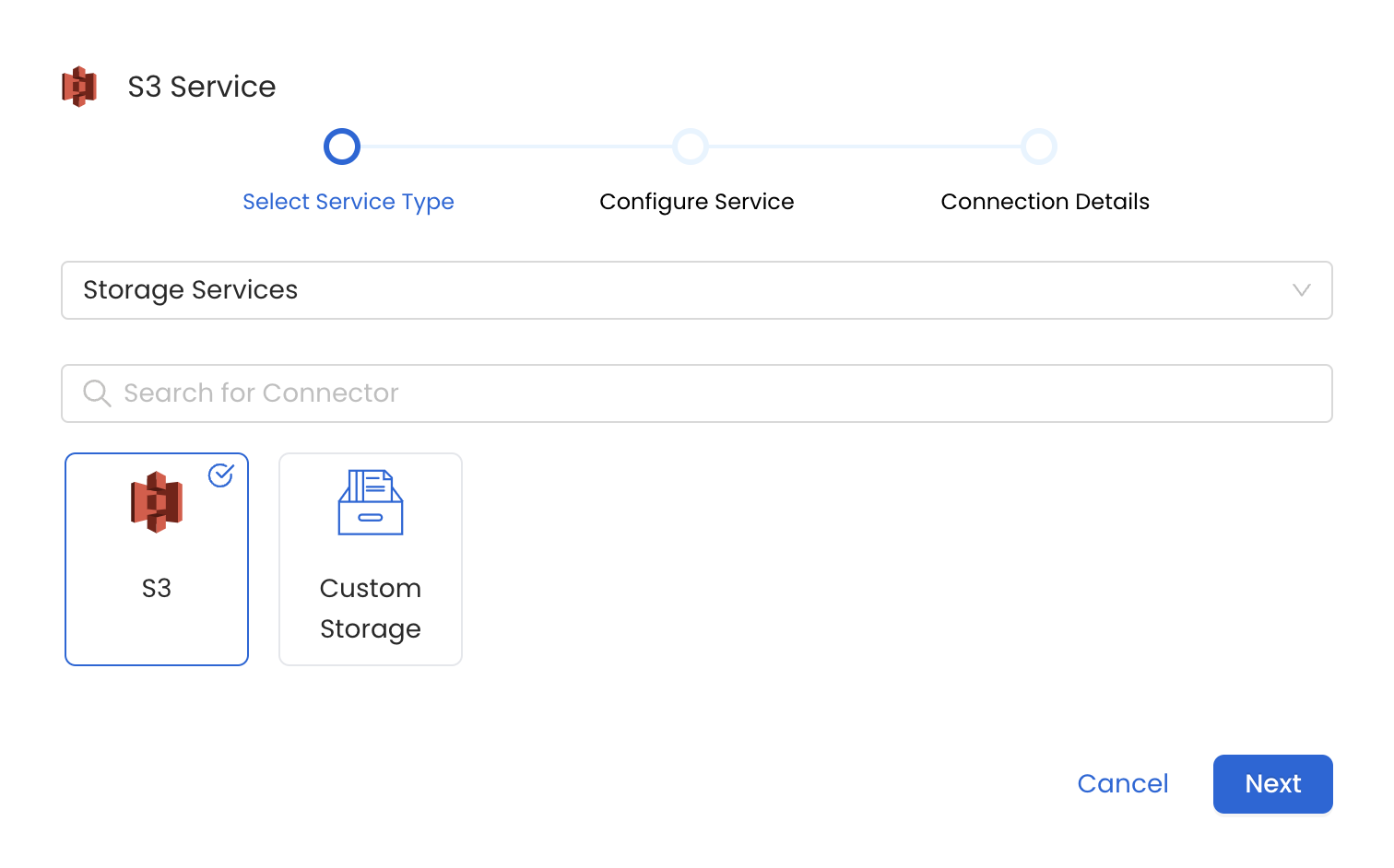
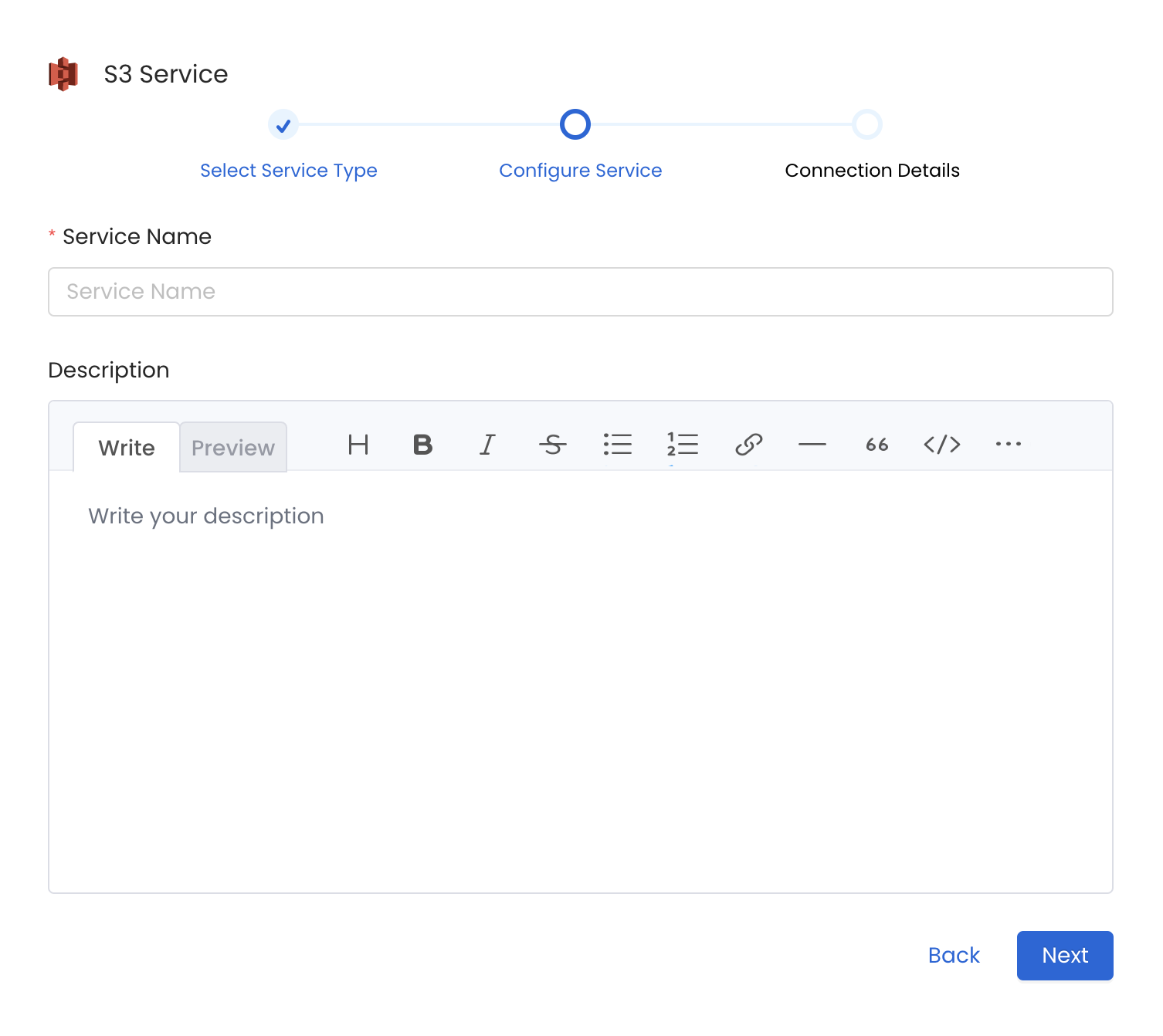
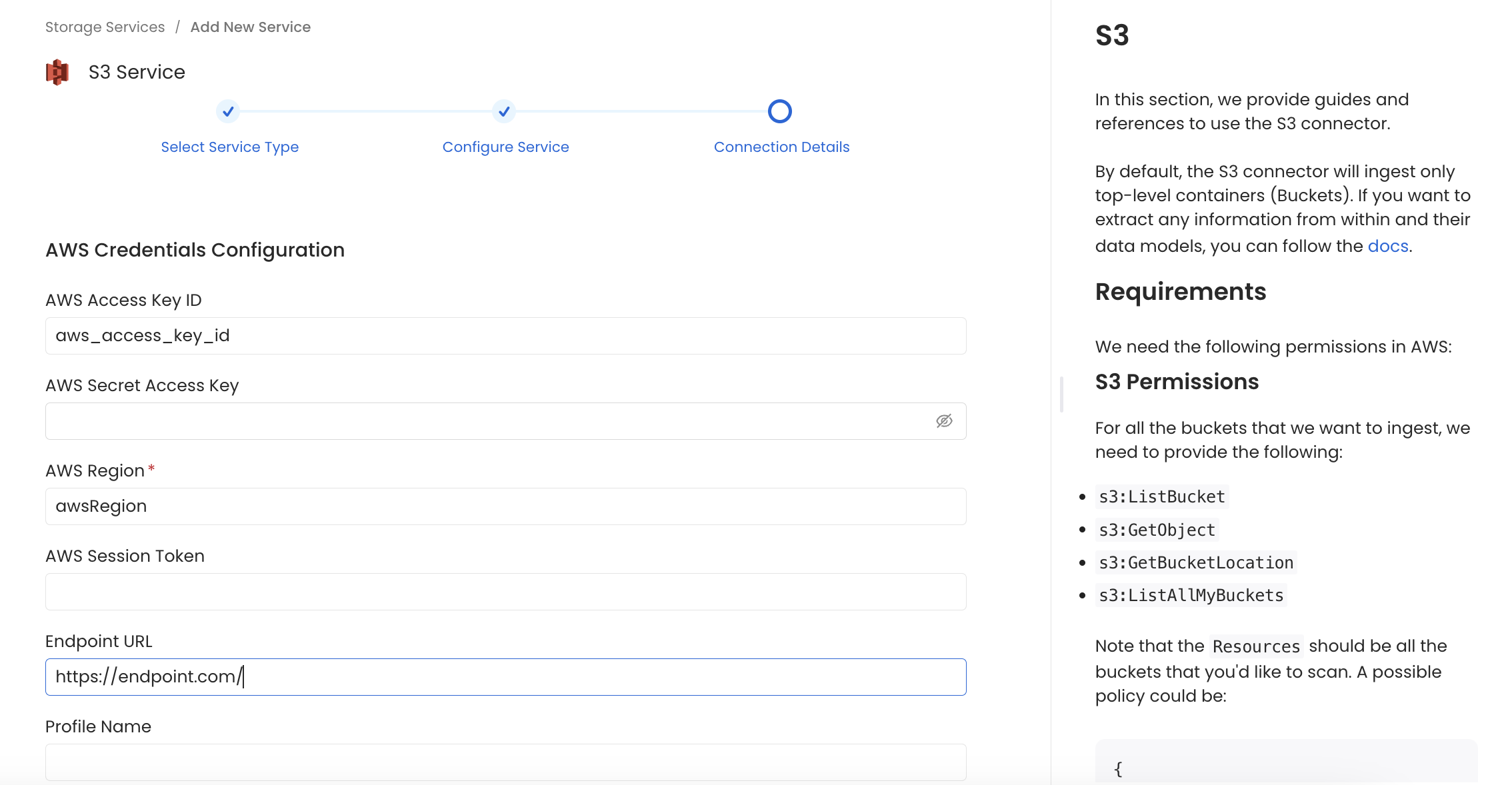
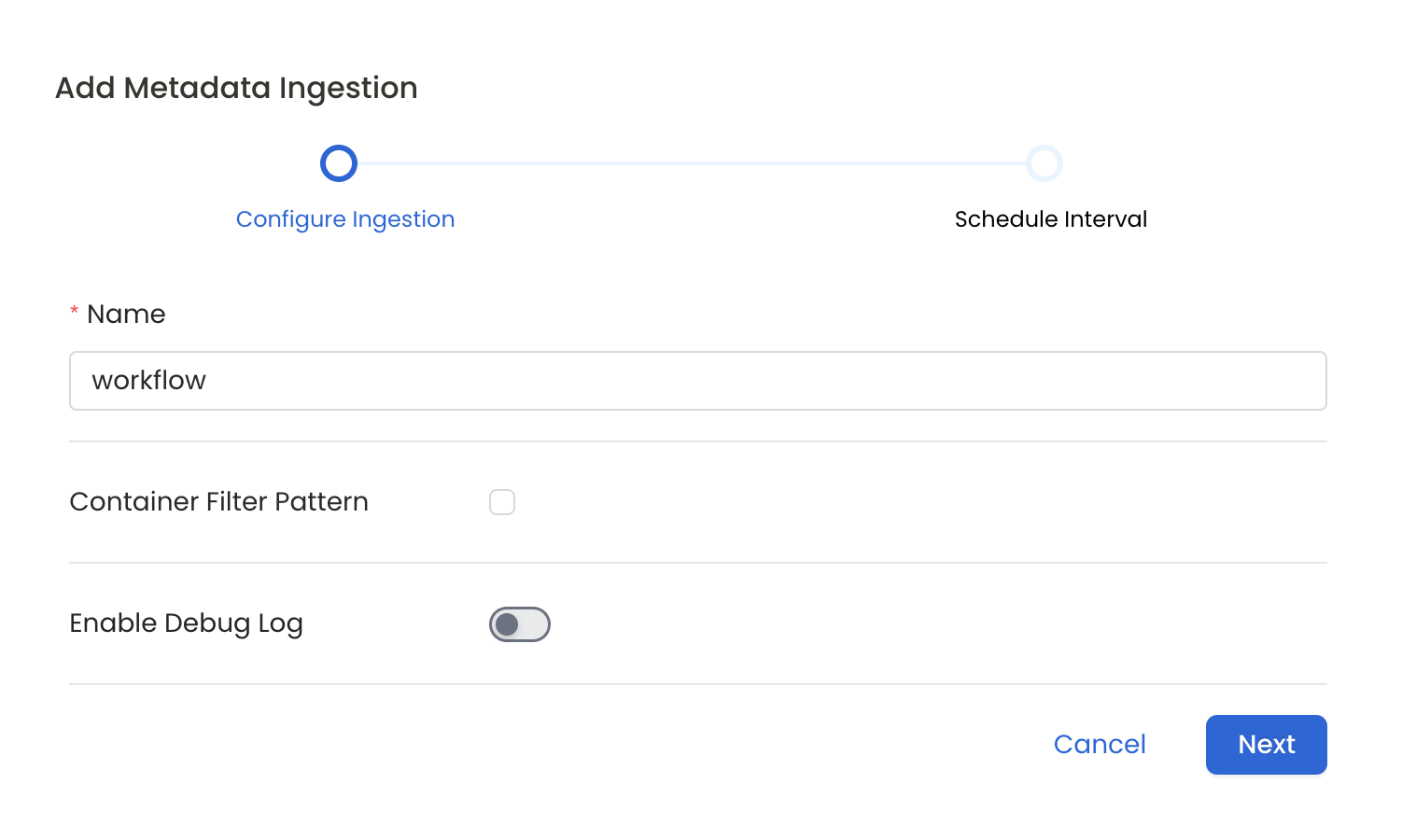 #### Metadata Ingestion Options
* **Name**: This field refers to the name of ingestion pipeline, you can customize the name or use the generated name.
* **Container Filter Pattern (Optional)**: To control whether to include a container as part of metadata ingestion.
* **Include**: Explicitly include containers by adding a list of comma-separated regular expressions to the Include field. OpenMetadata will include all containers with names matching one or more of the supplied regular expressions. All other containers will be excluded.
* **Exclude**: Explicitly exclude containers by adding a list of comma-separated regular expressions to the Exclude field. OpenMetadata will exclude all containers with names matching one or more of the supplied regular expressions. All other containers will be included.
* **Enable Debug Log (toggle)**: Set the Enable Debug Log toggle to set the default log level to debug.
* **Storage Metadata Config Source**: Here you can specify the location of your global manifest `openmetadata_storage_manifest.json` file. It can be located in S3, a local path or HTTP.
#### Metadata Ingestion Options
* **Name**: This field refers to the name of ingestion pipeline, you can customize the name or use the generated name.
* **Container Filter Pattern (Optional)**: To control whether to include a container as part of metadata ingestion.
* **Include**: Explicitly include containers by adding a list of comma-separated regular expressions to the Include field. OpenMetadata will include all containers with names matching one or more of the supplied regular expressions. All other containers will be excluded.
* **Exclude**: Explicitly exclude containers by adding a list of comma-separated regular expressions to the Exclude field. OpenMetadata will exclude all containers with names matching one or more of the supplied regular expressions. All other containers will be included.
* **Enable Debug Log (toggle)**: Set the Enable Debug Log toggle to set the default log level to debug.
* **Storage Metadata Config Source**: Here you can specify the location of your global manifest `openmetadata_storage_manifest.json` file. It can be located in S3, a local path or HTTP.