 #### Expected Steps to Resolve
To resolve this issue:
* Ensure that Airflow is restarted properly after an unexpected shutdown.
* Manually update the pipeline status if necessary.
* Check Airflow logs to verify if the DAG execution was interrupted.
#### Update `sort_buffer_size` (MySQL) or `work_mem` (Postgres)
Before running the migrations, it is important to update these parameters to ensure there are no runtime errors.
A safe value would be setting them to 20MB.
**If using MySQL**
You can update it via SQL (note that it will reset after the server restarts):
```sql theme={null}
SET GLOBAL sort_buffer_size = 20971520
```
To make the configuration persistent, you'd need to navigate to your MySQL Server install directory and update the
`my.ini` or `my.cnf` [files](https://dev.mysql.com/doc/refman/8.0/en/option-files.html) with `sort_buffer_size = 20971520`.
If using RDS, you will need to update your instance's [Parameter Group](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithParamGroups.html)
to include the above change.
**If using Postgres**
You can update it via SQL (not that it will reset after the server restarts):
```sql theme={null}
SET work_mem = '20MB';
```
To make the configuration persistent, you'll need to update the `postgresql.conf` [file](https://www.postgresql.org/docs/9.3/config-setting.html)
with `work_mem = 20MB`.
If using RDS, you will need to update your instance's [Parameter Group](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithParamGroups.html)
to include the above change.
Note that this value would depend on the size of your `query_entity` table. If you still see `Out of Sort Memory Error`s
during the migration after bumping this value, you can increase them further.
After the migration is finished, you can revert this changes.
#### Enable `pg_trgm` Extension (Azure PostgreSQL Flexible Server)
#### Expected Steps to Resolve
To resolve this issue:
* Ensure that Airflow is restarted properly after an unexpected shutdown.
* Manually update the pipeline status if necessary.
* Check Airflow logs to verify if the DAG execution was interrupted.
#### Update `sort_buffer_size` (MySQL) or `work_mem` (Postgres)
Before running the migrations, it is important to update these parameters to ensure there are no runtime errors.
A safe value would be setting them to 20MB.
**If using MySQL**
You can update it via SQL (note that it will reset after the server restarts):
```sql theme={null}
SET GLOBAL sort_buffer_size = 20971520
```
To make the configuration persistent, you'd need to navigate to your MySQL Server install directory and update the
`my.ini` or `my.cnf` [files](https://dev.mysql.com/doc/refman/8.0/en/option-files.html) with `sort_buffer_size = 20971520`.
If using RDS, you will need to update your instance's [Parameter Group](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithParamGroups.html)
to include the above change.
**If using Postgres**
You can update it via SQL (not that it will reset after the server restarts):
```sql theme={null}
SET work_mem = '20MB';
```
To make the configuration persistent, you'll need to update the `postgresql.conf` [file](https://www.postgresql.org/docs/9.3/config-setting.html)
with `work_mem = 20MB`.
If using RDS, you will need to update your instance's [Parameter Group](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithParamGroups.html)
to include the above change.
Note that this value would depend on the size of your `query_entity` table. If you still see `Out of Sort Memory Error`s
during the migration after bumping this value, you can increase them further.
After the migration is finished, you can revert this changes.
#### Enable `pg_trgm` Extension (Azure PostgreSQL Flexible Server)
 Before initiating the process by clicking `Run Now`, ensure that the `Recreate Indexes` option is enabled to allow rebuilding the indexes as needed.
In the configuration section, you can select the entities you want to reindex.
Before initiating the process by clicking `Run Now`, ensure that the `Recreate Indexes` option is enabled to allow rebuilding the indexes as needed.
In the configuration section, you can select the entities you want to reindex.
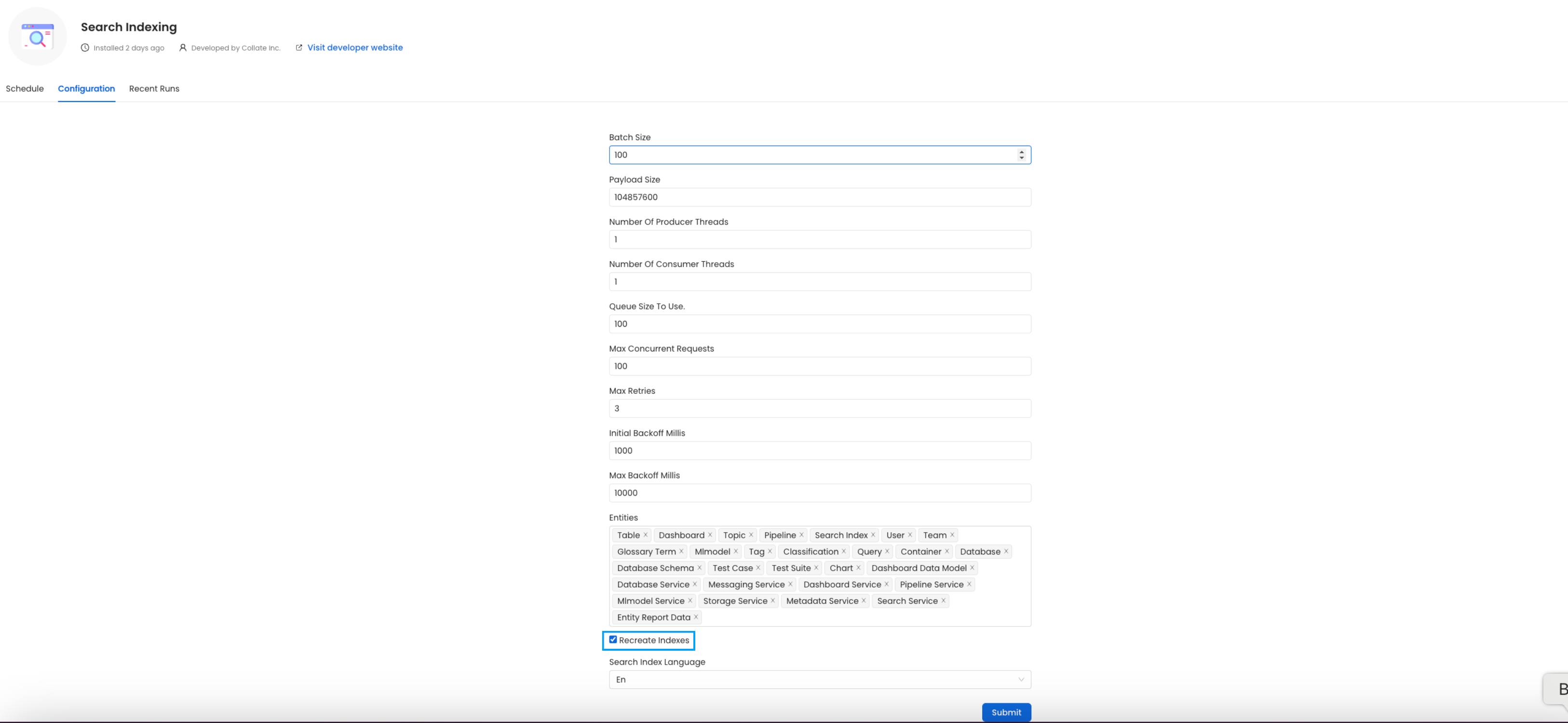 Since this is required after the upgrade, we want to reindex `All` the entities.
### (Optional) Update your OpenMetadata Ingestion Client
If you are running the ingestion workflows **externally** or using a custom Airflow installation, you need to make sure that the Python Client you use is aligned
with the OpenMetadata server version.
For example, if you are upgrading the server to the version `x.y.z`, you will need to update your client with
```bash theme={null}
pip install openmetadata-ingestion[
Since this is required after the upgrade, we want to reindex `All` the entities.
### (Optional) Update your OpenMetadata Ingestion Client
If you are running the ingestion workflows **externally** or using a custom Airflow installation, you need to make sure that the Python Client you use is aligned
with the OpenMetadata server version.
For example, if you are upgrading the server to the version `x.y.z`, you will need to update your client with
```bash theme={null}
pip install openmetadata-ingestion[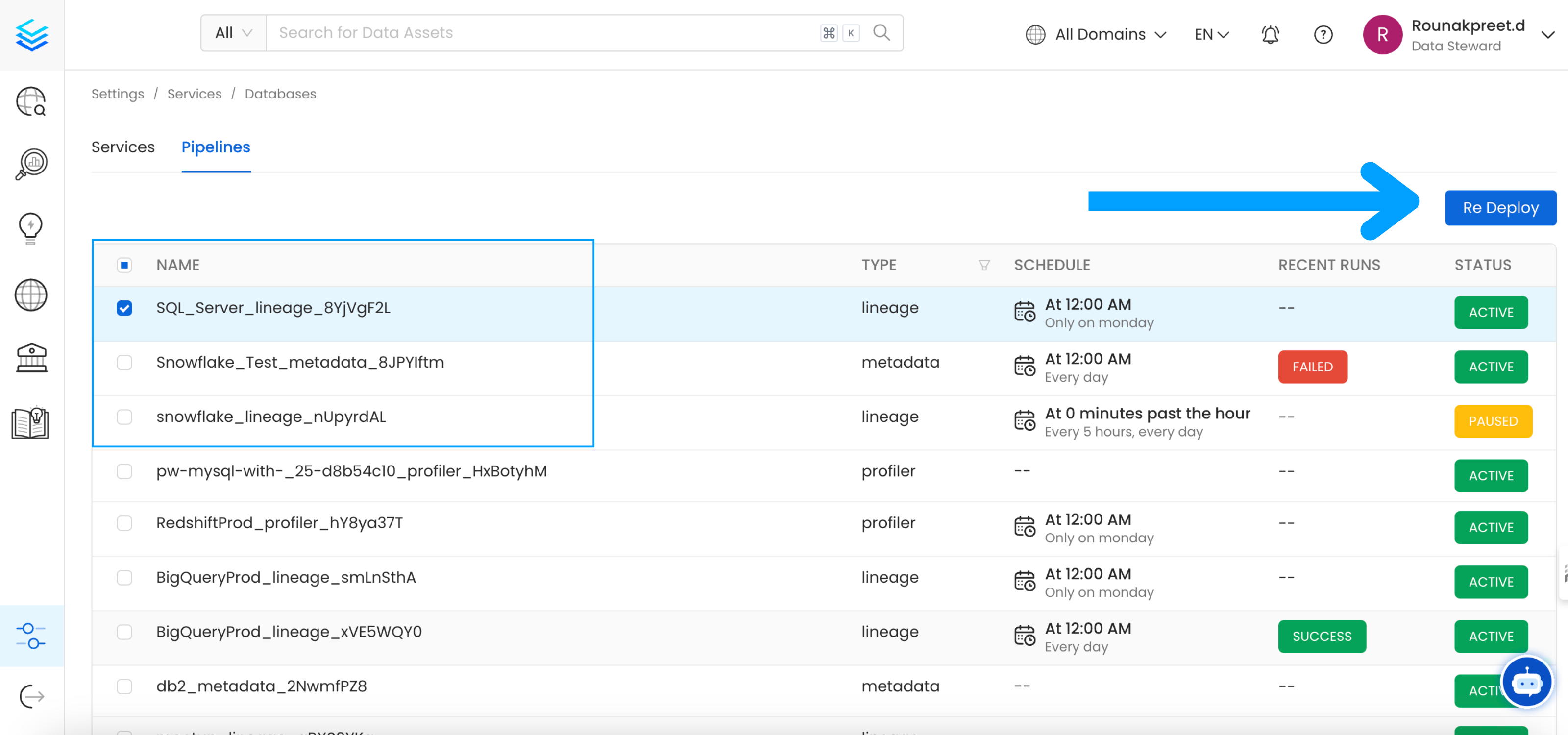 Select the pipelines you want to Re Deploy click `Re Deploy`.
#### With Kubernetes
Follow these steps to deploy pipelines using the CLI:
1. List the CronJobs
Use the following command to check the available CronJobs:
```bash theme={null}
kubectl get cronjobs
```
Upon running this command you should see output similar to the following.
```commandline theme={null}
kubectl get cronjobs
NAME SCHEDULE TIMEZONE SUSPEND ACTIVE LAST SCHEDULE AGE
cron-deploy-pipelines 0/5 * * * *
Select the pipelines you want to Re Deploy click `Re Deploy`.
#### With Kubernetes
Follow these steps to deploy pipelines using the CLI:
1. List the CronJobs
Use the following command to check the available CronJobs:
```bash theme={null}
kubectl get cronjobs
```
Upon running this command you should see output similar to the following.
```commandline theme={null}
kubectl get cronjobs
NAME SCHEDULE TIMEZONE SUSPEND ACTIVE LAST SCHEDULE AGE
cron-deploy-pipelines 0/5 * * * *