Setup Multiple dbt Projects
You can set up the dbt workflow to ingest metadata from multiple dbt projects, each containing multiple manifest.json, catalog.json, and run_results.json files.
This functionality is supported for s3, GCS, and Azure configurations only.
To ensure the workflow operates smoothly, organize the dbt files for each project into separate directories and name the files manifest.json, catalog.json, and run_results.json.
If your dbt tests are split across multiple run_results.json files, place these files in the same directory as their corresponding manifest.json file. Ensure that each file retains run_results in its name, and append a unique suffix as needed. For example: run_results_one.json, run_results_two.json, run_results_three.json
The workflow will scan through the specified prefix path in the designated bucket, traversing each folder to locate these dbt files.
The dbt workflow will scan through the provided prefix path in the specified bucket and go through each folder to find the dbt files.
Here's an example of setting up the dbt workflow for multiple dbt projects in an s3 configuration:
1. Organizing the dbt Files in the S3 Bucket
Place the dbt files (manifest.json, catalog.json, and run_results.json) in separate directories within the S3 bucket.
For this example, let's explore a directory structure where we have set up three distinct dbt projects: dbt_project_one, dbt_project_two, and dbt_project_three. We will configure the dbt workflow to pickup the dbt files from each of these directories.
Bucket name: dbt_bucket
2. Setup the configuration in OpenMetadata
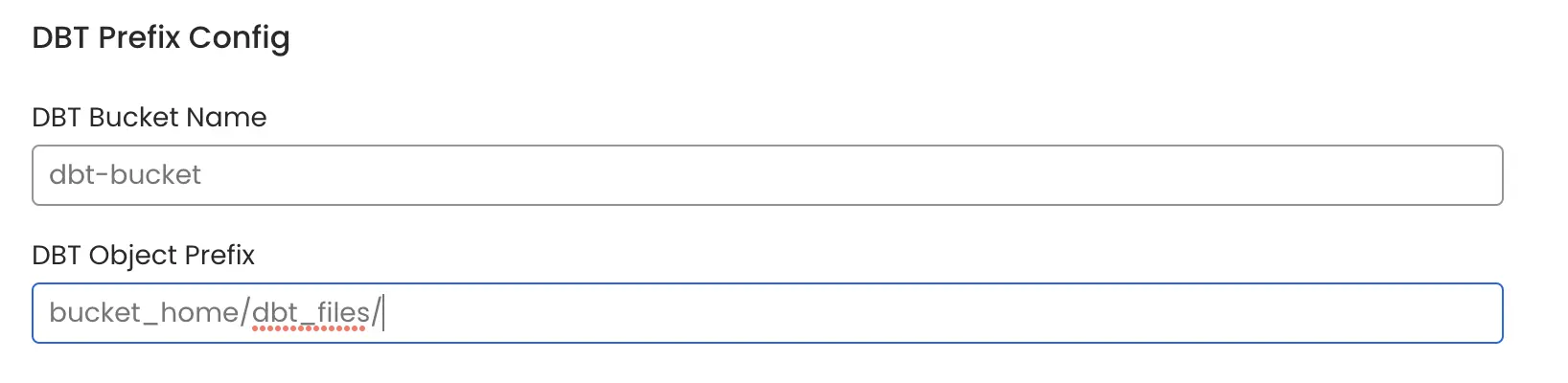
In the
dbt Bucket Namefield, enter the name of your bucket, which in this case isdbt_bucket.Specify the
dbt Object Prefixpath for the parent folder where your dbt projects are located. In this example, the prefix path should be set tobucket_home/dbt_files/.
If you wish to scan the entire bucket, only enter the dbt Bucket Name and keep the dbt Object Prefix field empty.
dbt Multiple Projects Prefix Example
3. Run the dbt Workflow
After running the dbt workflow, the dbt metadata from all the three projects will be ingested.