Best Practices for Glossary
A controlled vocabulary is an organized arrangement of words and phrases to define terminology to organize and retrieve information. Glossary and Classification are both controlled vocabulary.
Here are the Top 8 Best Practices around Terminologies:
1. Use Hierarchical Relationships
A hierarchical structure helps in grouping similar concepts and helps in better understanding. Instead of using a flat list of glossary terms, add a hierarchical (Parent-Child) relationship. This provides more context to a glossary term. The additional context helps in classification and policy enforcement.
When using hierarchy, it is better to limit the hierarchy to three levels.
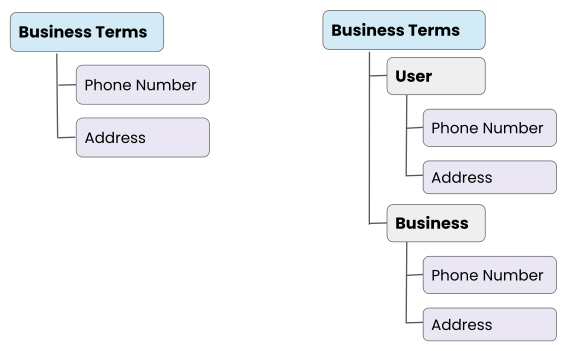
Phone Number in the Context of a User and Business
In a flat list, the term ‘Phone Number’ lacks context and it would be difficult to ascertain the sensitivity of data. A ‘User Phone Number’ is PII-Sensitive, whereas a ‘Business Phone Number’ is not PII-Sensitive. This can be best represented with hierarchical relationships and by grouping concepts.
2. Add Classification Tags to Glossary Terms
Classification tags can be added to a glossary term. This helps to define both the semantic meaning and type of data in a single step. Instead of adding classification tags manually, a glossary term can be added to define the meaning of the data, and classification tags like PII-sensitive can be added to the term to define the type of data. This helps to auto-assign PII tags.
Organizations have data producers who create tables, and build data models. Team members who understand regulatory compliance requirements are good at classifying data. Among them, those who understand the data as well as the regulatory requirements, can help organizations scale by adding glossary terms along with the classification and tags.
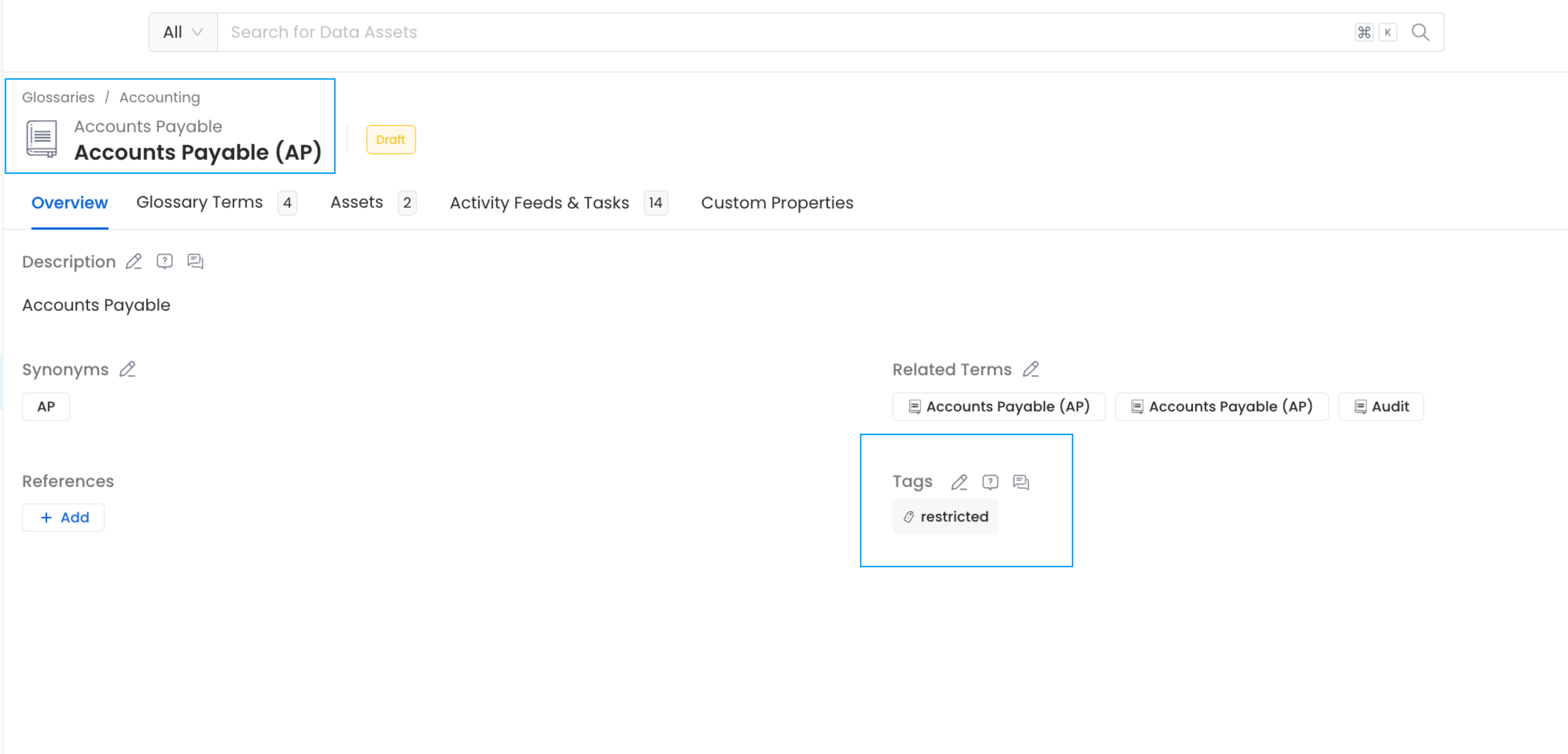
Add Classification Tags to Glossary Terms
3. Make Use of Tier Classification
Tiering helps define the importance of data to an organization. By focusing on Tier 1 data, organizations can create the highest impact. Identifying Tier 5 can help declutter the existing data. Learn more about Tiers.
4. Use Classifications to Simplify Policies
Along with ownership and team membership, tags are a powerful way to group data assets. A single policy can be created at the Resource level instead of managing multiple policies for various resources.
Resources can be grouped using classification tags like sensitive data, restrictive data, external data, raw data, public data, internal data, etc. Further, Policies can be created based on Tags to simplify data governance.
Instead of creating policies for separate tables with sensitive data, the ‘Sensitive’ tag can be attached to various data assets; and a policy can be created to match based on the Sensitive tag, which will take care of all the resources marked accordingly.
5. Use Display Name to Improve Names
When glossaries are inherited from source systems, the names may not communicate the concept well. For example, dep-prod instead of Product Department. Users are more likely to search using common terms like Product or Department, and this helps in better discovery.
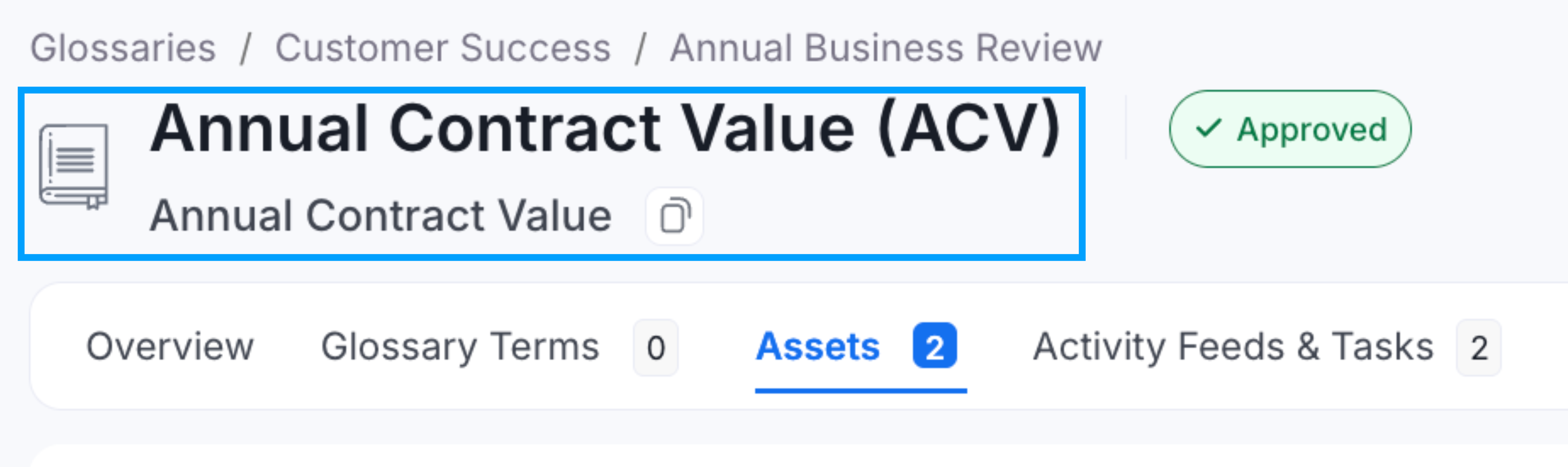
Add Display Names for Better Discovery
In cases where abbreviations or acronyms are used, a better display name helps in data discovery. For example, c_id can be changed to Customer ID, and CAC can be changed to Customer Acquisition Cost
6. Use Glossary Import Export
For glossary bulk edits to update descriptions, ownership, reviewer, and status, export the Glossary, make the edits in a CSV file, and import it. Learn more about Glossary Bulk Import.
7. Don’t Delete Glossary Terms; Rename them
When glossary terms have typos, users tend to delete the term. All the effort spent in tagging the data assets is lost when terms are deleted. OpenMetadata supports renaming Glossary terms. Simply rename the terms.
8. Group Similar Concepts Together
When adding terms, building a semantic relationship helps to understand data through concepts. For example, grouping related terms helps in understanding the various terms and their overall relationship.
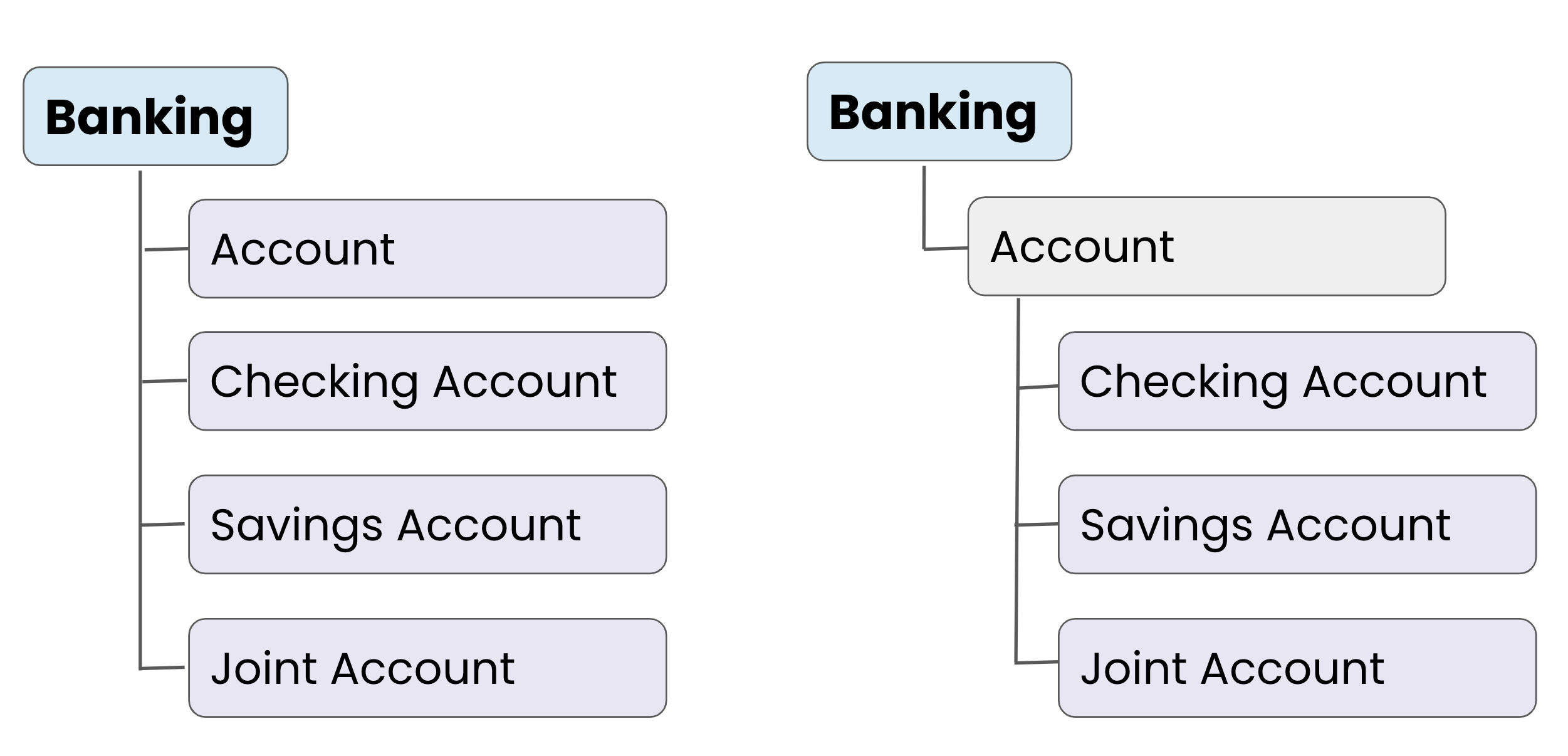
Group Similar Concepts Together