Metadata Ingestion - Multithreading (Beta)
The default Metadata Ingestion runs sequentially. This feature allows to run the ingestion concurrently using Threading.
The user is able to define the amount of threads he would like to use and then the ingestion pipeline is responsible for opening at most that amount. The specific behaviour changes depending on the Service Type used. Please check below on Feature available for for more information.
General Considerations
Each case is specific and more threads does not necessarily translate into a better performance.
Take into account that with each thread we
- Increase the load on the Database, since it opens a new connection that will be used.
- Increases the Memory used, since we are holding more context at any given time.
We recommend testing with different values from 1 to 8. If unsure or having issues, leaving it at 1 is recommended.
Feature available for
Databases
This feature is implemented for all Databases at schema level. This means that instead of processing one schema at a time we open at most the amount number of configured threads, each with a dedicated Database connection and process them concurrently.
Example: 4 Threads
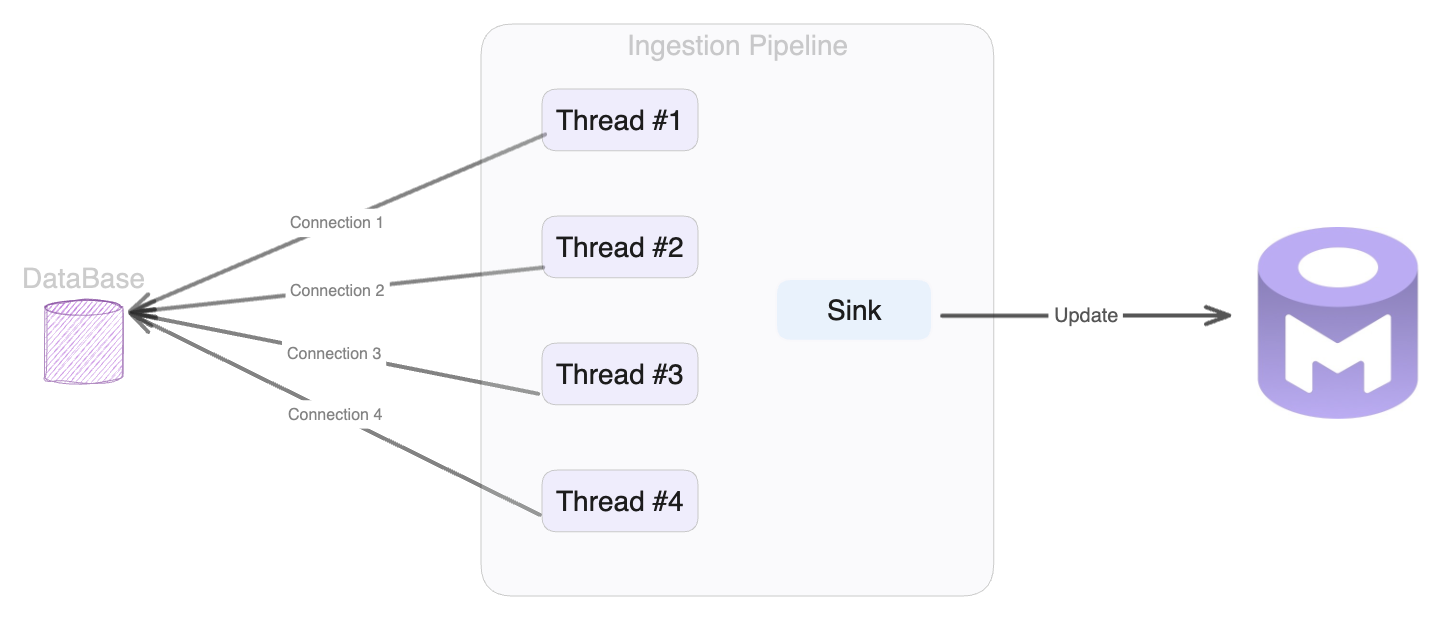
Small Diagram to depict how multithreading works.