Spark Lineage Ingestion
A spark job may involve movement/transfer of data which may result into a data lineage, to capture such lineages you can make use of OpenMetadata Spark Agent which you can configure with your spark session and capture these spark lineages into your OpenMetadata instance.
In this guide we will explain how you can make use of the OpenMetadata Spark Agent to capture such lineage.
- Requirements
- Configuration
- Configuration Parameters
- Using Spark Agent with Databricks
- Using Spark Agent with Glue
- Troubleshooting
Requirements
To use the OpenMetadata Spark Agent, you will have to download the latest jar from here.
We support Spark version 3.1 and above.
Configuration
While configuring the spark session, in this guide we will make use of PySpark to demonstrate the use of OpenMetadata Spark Agent
Once you have downloaded the jar from here in your spark configuration you will have to add the path to your openmetadata-spark-agent.jar along with other required jars to run your spark job, in this example it is mysql-connector-java.jar
openmetadata-spark-agent.jar comes with a custom spark listener i.e. io.openlineage.spark.agent.OpenLineageSparkListener you will need to add this as extraListeners spark configuration.
spark.openmetadata.transport.hostPort: Specify the host & port of the instance where your OpenMetadata is hosted.
spark.openmetadata.transport.type is required configuration with value as openmetadata.
spark.openmetadata.transport.jwtToken: Specify your OpenMetadata Jwt token here. Checkout this documentation on how you can generate a jwt token in OpenMetadata.
spark.openmetadata.transport.pipelineServiceName: This spark job will be creating a new pipeline service of type Spark, use this configuration to customize the pipeline service name.
Note: If the pipeline service with the specified name already exists then we will be updating/using the same pipeline service.
spark.openmetadata.transport.pipelineName: This spark job will also create a new pipeline within the pipeline service defined above. Use this configuration to customize the name of pipeline.
Note: If the pipeline with the specified name already exists then we will be updating/using the same pipeline.
spark.openmetadata.transport.pipelineSourceUrl: You can use this configuration to provide additional context to your pipeline by specifying a url related to the pipeline.
spark.openmetadata.transport.pipelineDescription: Provide pipeline description using this spark configuration.
spark.openmetadata.transport.databaseServiceNames: Provide the comma separated list of database service names which contains the source tables used in this job. If you do not provide this configuration then we will be searching through all the services available in openmetadata.
spark.openmetadata.transport.timeout: Provide the timeout to communicate with OpenMetadata APIs.
In this job we are reading data from employee table and moving it to another table employee_new of within same mysql source.
Once this pyspark job get finished you will see a new pipeline service with name my_pipeline_service generated in your openmetadata instance which would contain a pipeline with name my_pipeline as per the above example and you should also see lineage between the table employee and employee_new via my_pipeline.
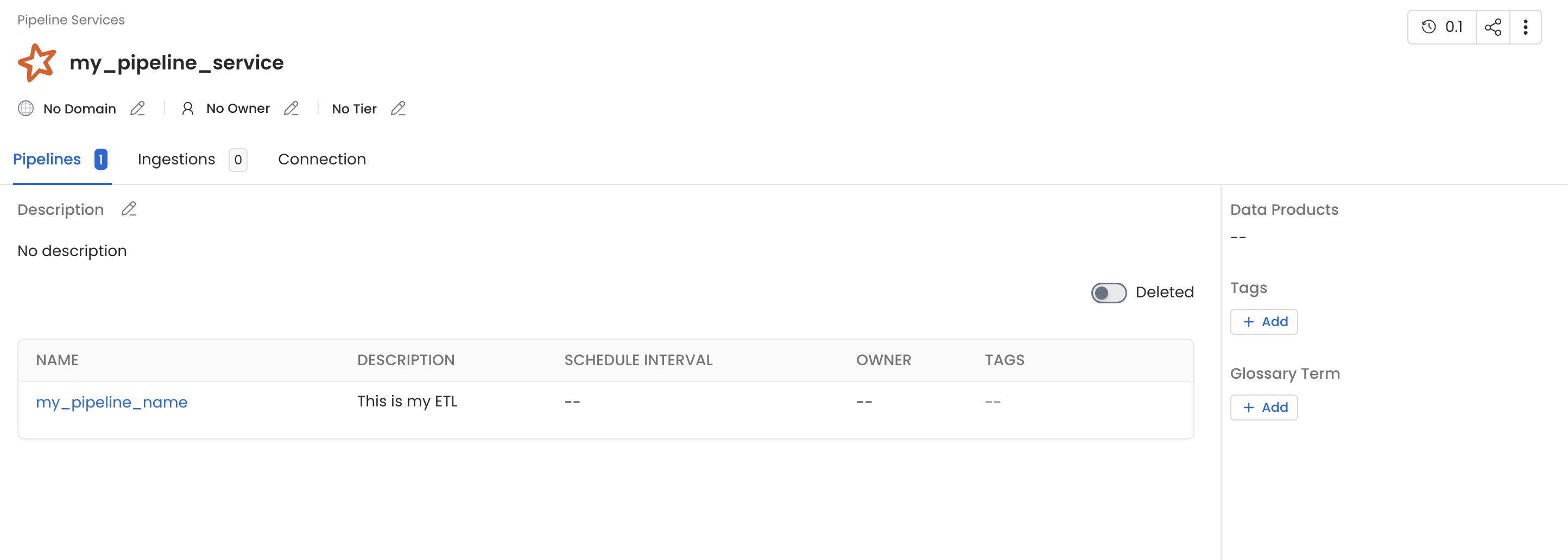
Spark Pipeline Service
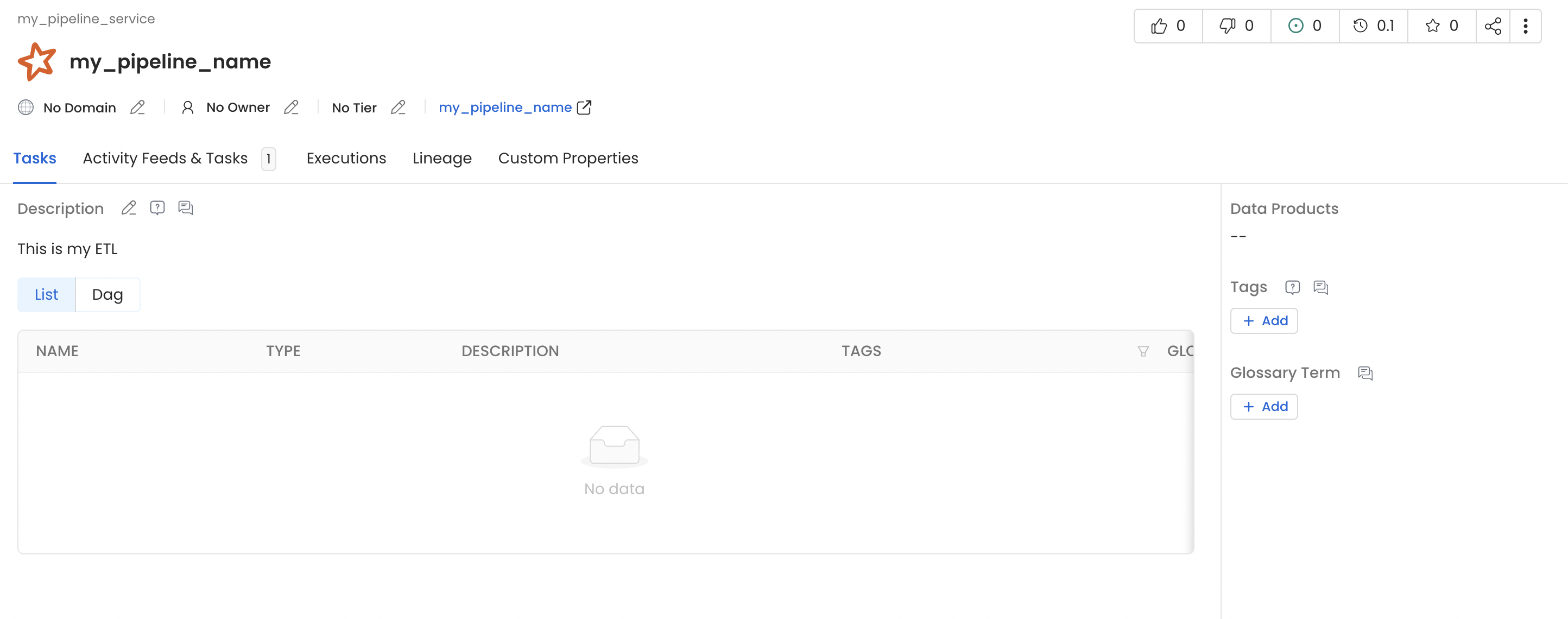
Spark Pipeline Details
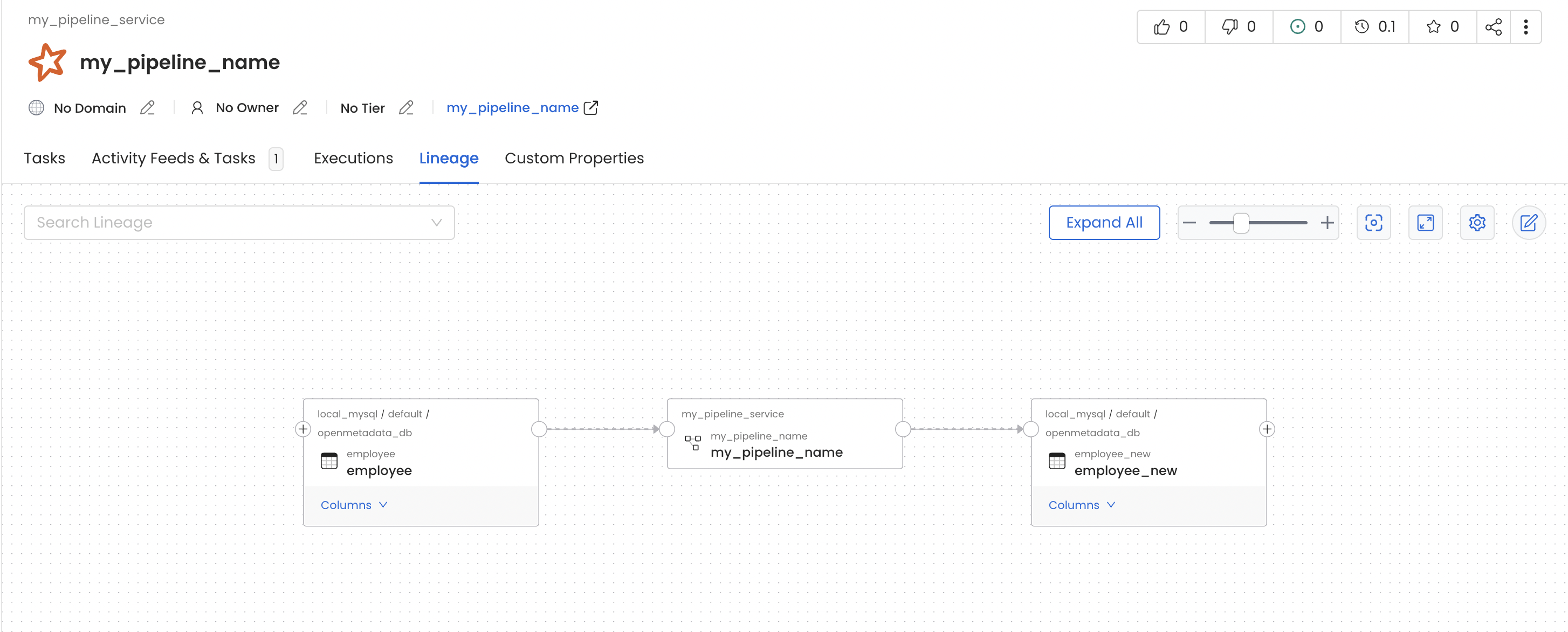
Spark Pipeline Lineage
Configuration Parameters
| Parameter | Required | Description |
|---|---|---|
spark.extraListeners | Yes | Must be set to io.openlineage.spark.agent.OpenLineageSparkListener |
spark.openmetadata.transport.type | Yes | Must be set to openmetadata |
spark.openmetadata.transport.hostPort | Yes | OpenMetadata server URL with /api suffix (e.g., http://localhost:8585/api) |
spark.openmetadata.transport.jwtToken | Yes | JWT token for authentication. Generate token |
spark.openmetadata.transport.pipelineServiceName | No | Name of the pipeline service to create/update |
spark.openmetadata.transport.pipelineName | No | Name of the pipeline to create/update |
spark.openmetadata.transport.pipelineDescription | No | Description for the pipeline |
spark.openmetadata.transport.databaseServiceNames | No | Comma-separated list of database services to search for tables |
spark.openmetadata.transport.timeout | No | Timeout in seconds for OpenMetadata API calls (default: 30) |
Using Spark Agent with Databricks
Follow the below steps in order to use OpenMetadata Spark Agent with databricks.
1. Upload the jar to compute cluster
To use the OpenMetadata Spark Agent, you will have to download the latest jar from here and upload it to your databricks compute cluster.
To upload the jar you can visit the compute details page and then go to the libraries tab
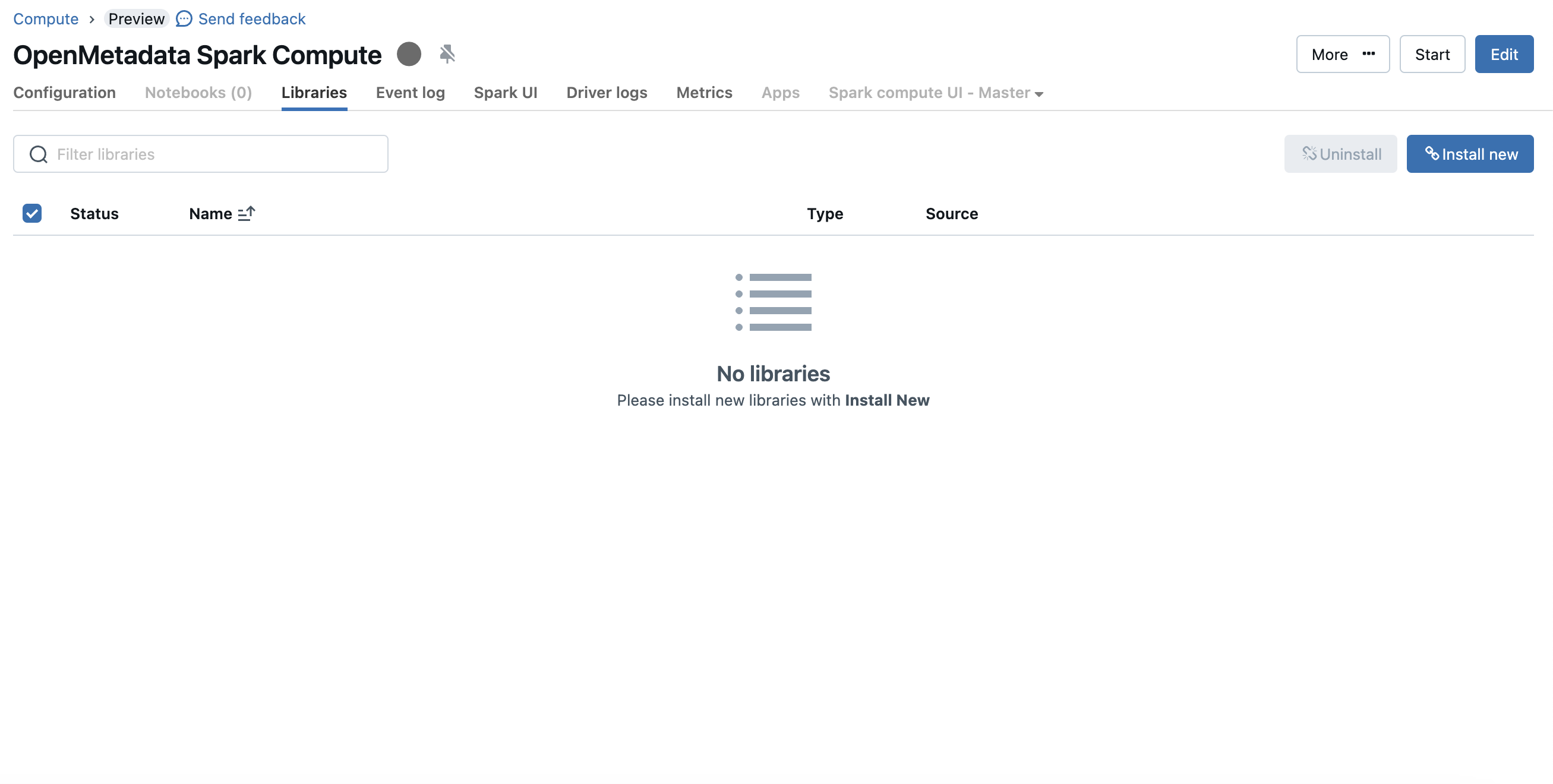
Spark Upload Jar
Click on the "Install Now" button and choose dbfs mode and upload the OpenMetadata Spark Agent jar.
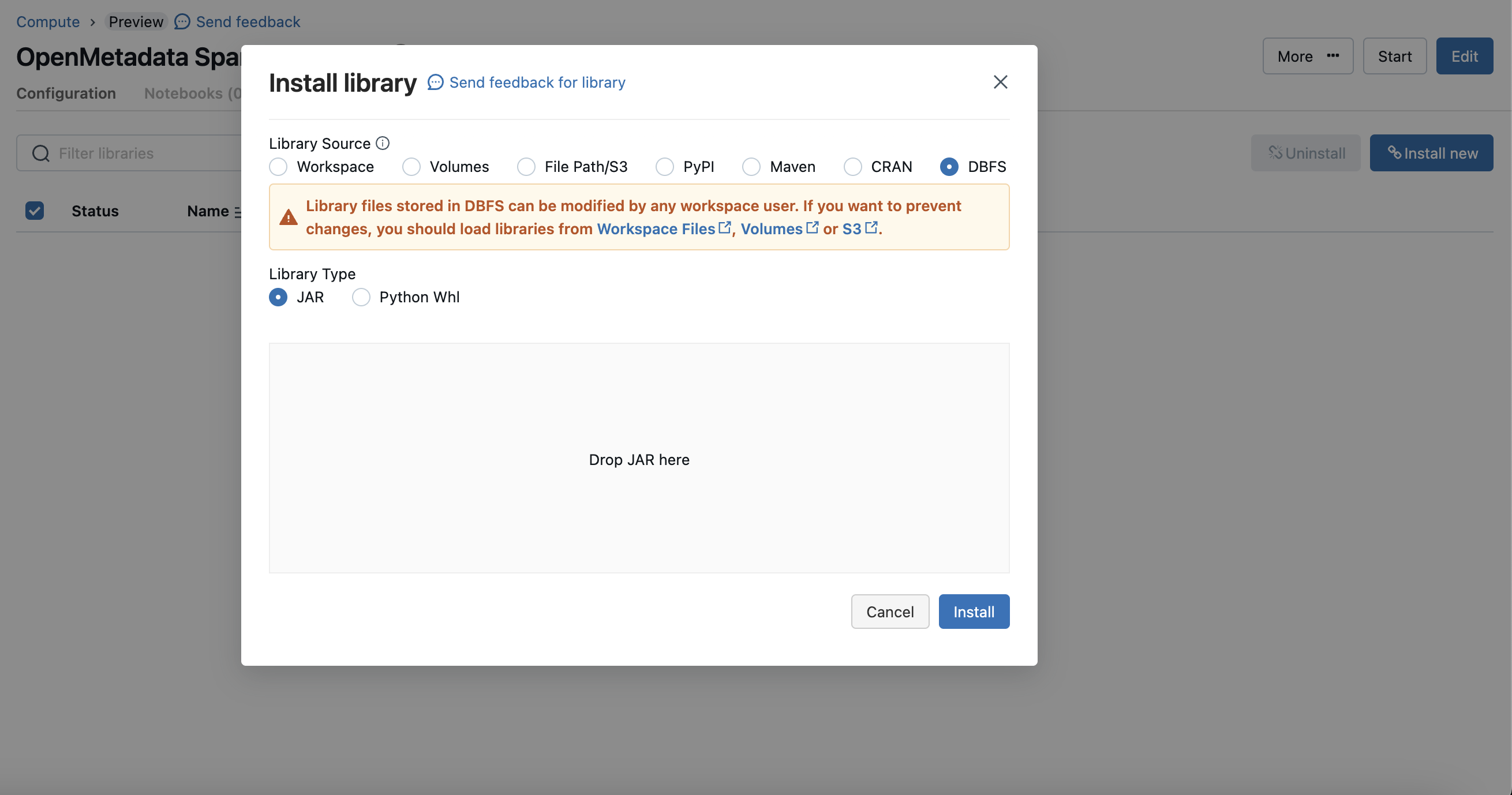
Spark Upload Jar
Once your jar is uploaded copy the path of the jar for the next steps.
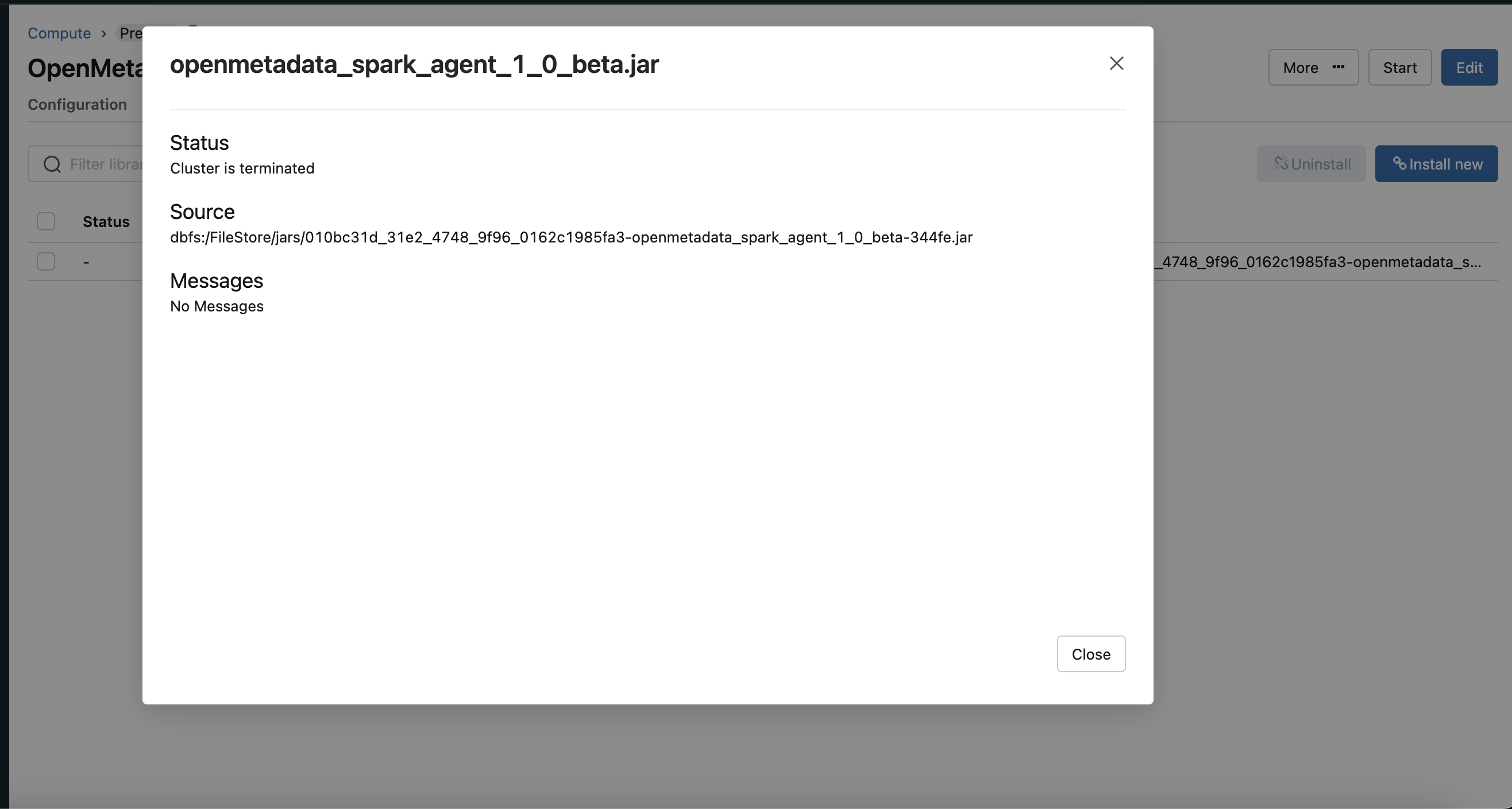
Spark Upload Jar
2. Create Initialization Script
Once your jar is uploaded you need to create a initialization script in your workspace.
Note: The copied path would look like this dbfs:/FileStore/jars/.... you need to modify it like /dbfs/FileStore/jars/... this.
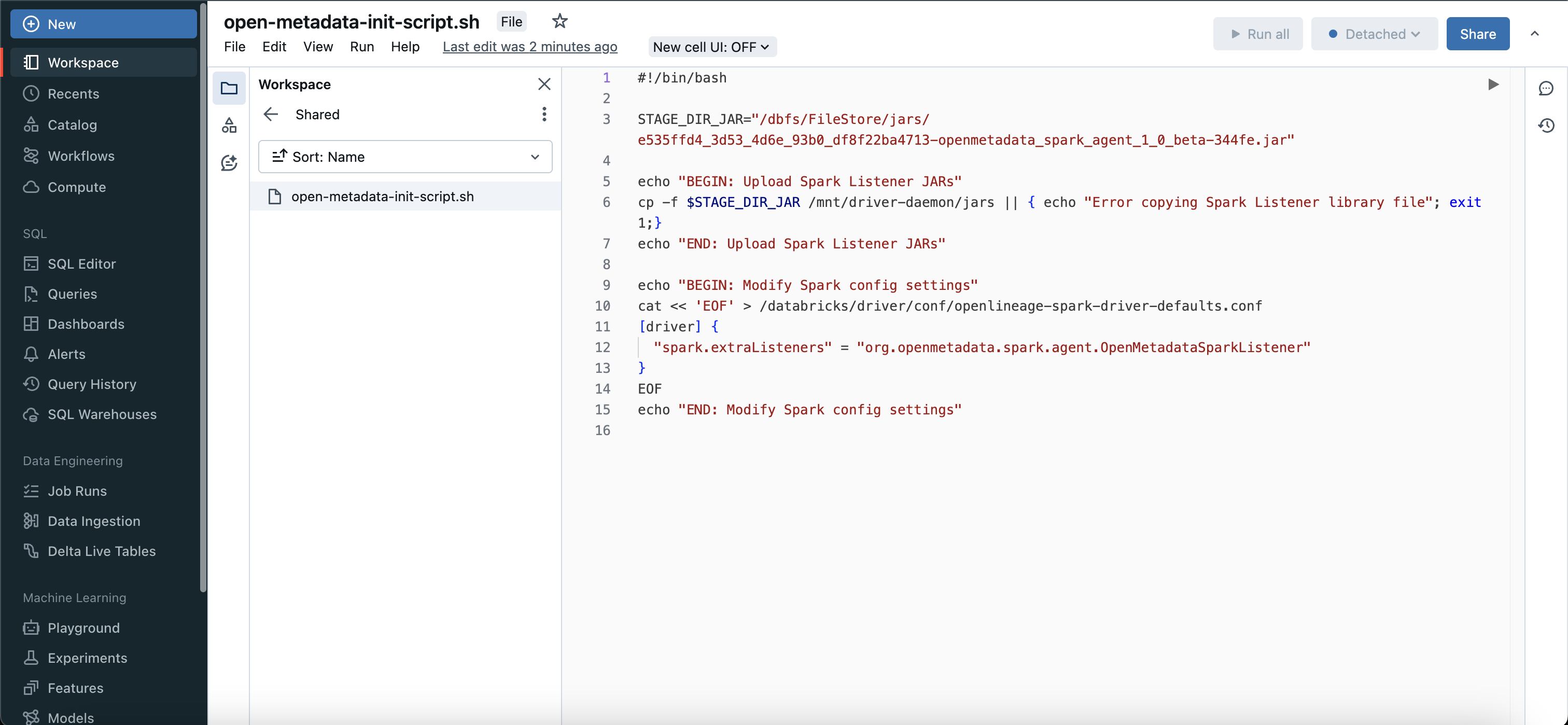
Prepare Script
3. Configure Initialization Script
Once you have created a initialization script, you will need to attach this script to your compute instance, to do that you can go to advanced config > init scripts and add your script path.
Prepare Script
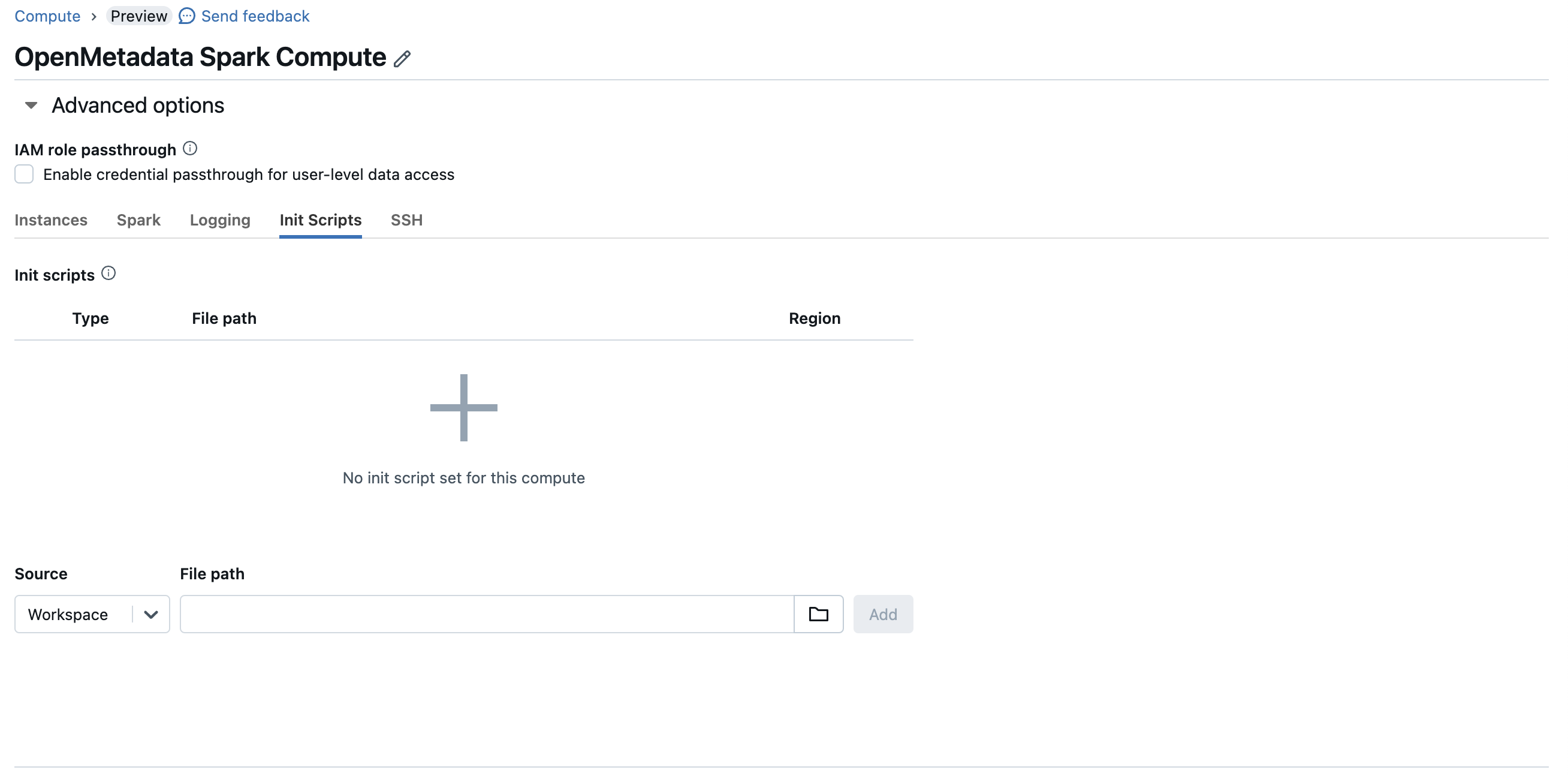
Spark Init Script
4. Configure Spark
After configuring the init script, you will need to update the spark config as well.
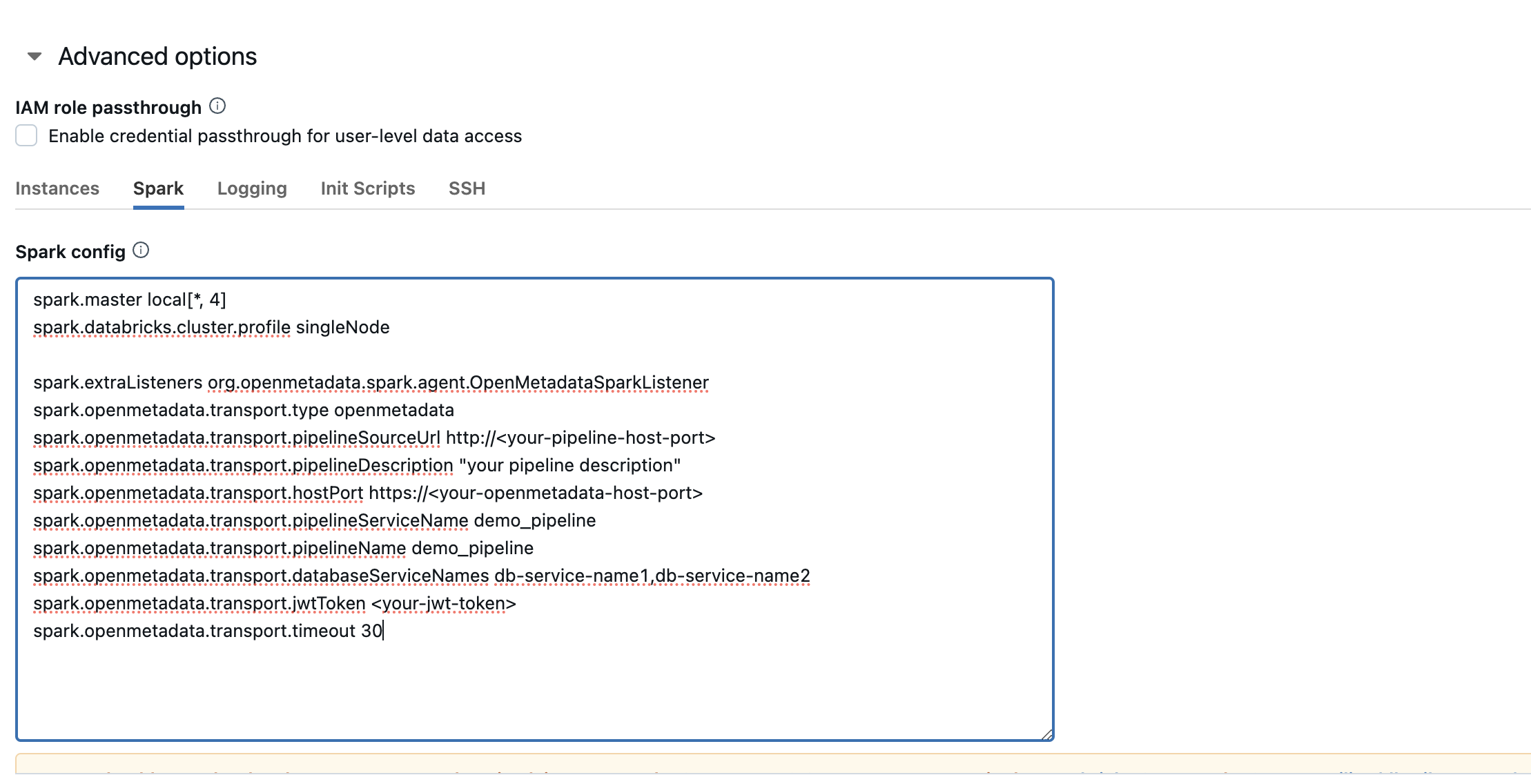
Spark Set Config
these are the possible configurations that you can do, please refer the Configuration section above to get the detailed information about the same.
After all these steps are completed you can start/restart your compute instance and you are ready to extract the lineage from spark to OpenMetadata.
Using Spark Agent with Glue
Follow the below steps in order to use OpenMetadata Spark Agent with glue.
1. Specify the OpenMetadata Spark Agent JAR URL
- Upload the OpenMetadata Spark Agent Jar to S3
- Navigate to the glue job,In the Job details tab, navigate to Advanced properties → Libraries → Dependent Jars path
- Add the S3 url of OpenMetadata Spark Agent Jar in the Dependent Jars path.
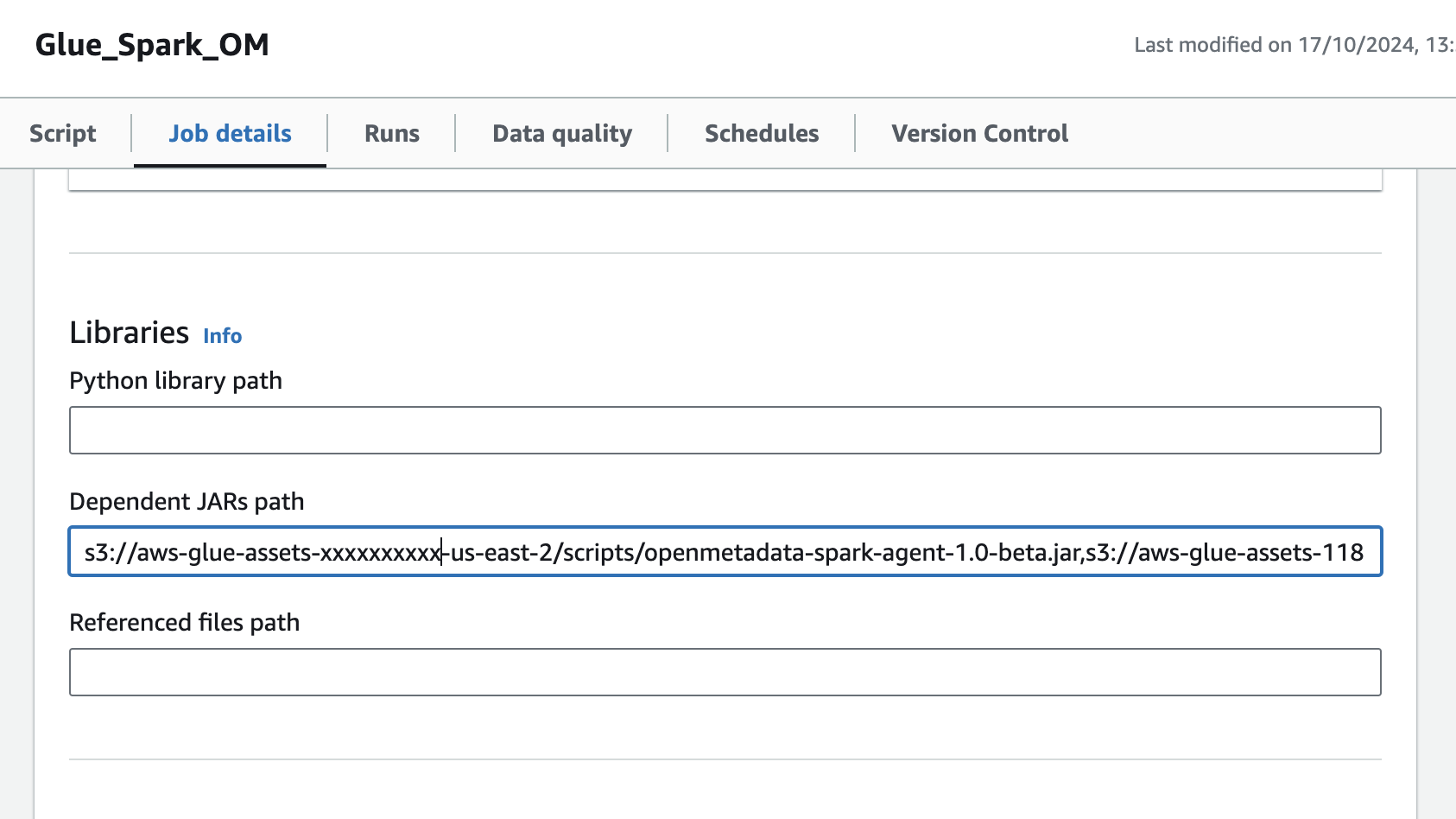
Glue Job Configure Jar
2. Add Spark configuration in Job Parameters
In the same Job details tab, add a new property under Job parameters:
- Add the
--confproperty with following value, make sure to customize this configuration as described in the above documentation.
- Add the
--user-jars-firstparameter and set its value totrue
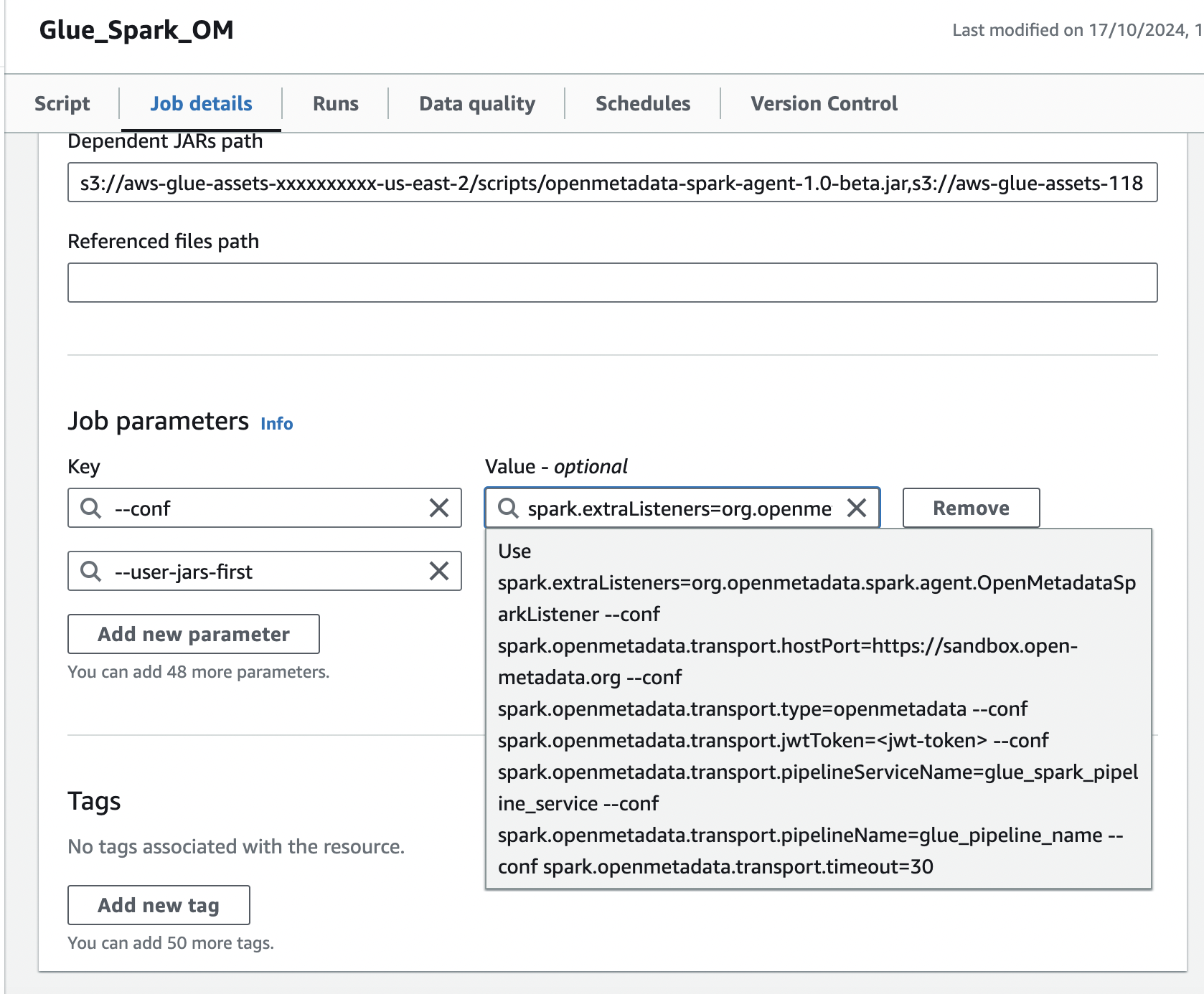
Glue Job Configure Params
Troubleshooting
Common Issues and Solutions
Issue 1: Lineage Not Appearing in OpenMetadata
Symptoms:
- Spark job runs successfully
- No pipeline or lineage visible in OpenMetadata UI
Diagnostic Steps:
Check Spark logs for OpenLineageSparkListener:
- If not found: Agent JAR not in classpath or
spark.extraListenersnot configured - Solution: Verify JAR path in
spark.jarsconfig and listener inspark.extraListeners
- If not found: Agent JAR not in classpath or
Verify OpenMetadata connectivity:
- If fails: Network connectivity issue or incorrect
hostPort - Solution: Check firewall rules, DNS resolution, and
spark.openmetadata.transport.hostPortconfig
- If fails: Network connectivity issue or incorrect
Check for error messages:
Issue 2: Authentication Failed (401 Unauthorized)
Symptoms:
- Logs show "401 Unauthorized" or "Invalid JWT token"
Solutions:
Verify JWT token is valid:
- If fails: Token is invalid or expired
Generate new JWT token:
- Go to OpenMetadata UI → Settings → Bots → ingestion-bot
- Click "Revoke & Generate New Token"
- Copy the new token and update your Spark configuration
Verify token format:
- Token should be a long string without spaces
- Ensure no extra quotes or newlines when copying
Issue 3: ClassNotFoundException: OpenLineageSparkListener
Symptoms:
Solutions:
Verify JAR is in classpath:
For YARN deployments:
For Kubernetes:
- Ensure JAR is in container image or mounted volume
- Verify volume mounts are correct
Issue 4: Pipeline Created But No Lineage
Symptoms:
- Pipeline service and pipeline exist in OpenMetadata
- No lineage edges visible
Solutions:
Verify database services exist:
- Check that source and target database services are configured in OpenMetadata
- Table names in Spark job must match those in OpenMetadata
Use
databaseServiceNamesconfiguration:- Helps agent find tables faster
- Reduces search scope
Check table naming:
- Ensure table names match exactly (case-sensitive)
- Include schema/database prefix if needed (e.g.,
database.table)
Issue 5: Timeout Errors
Symptoms:
Solutions:
Increase timeout:
Check OpenMetadata server performance:
- High load on OpenMetadata can cause slow responses
- Consider scaling OpenMetadata infrastructure
Network latency:
- If Spark and OpenMetadata are in different regions/networks
- Consider using VPN or dedicated network links
Issue 6: Memory Issues in Spark Job
Symptoms:
- OutOfMemoryError after adding OpenMetadata Agent
- Job runs slower than before
Solutions:
Increase executor memory:
The agent has minimal overhead (~50MB), but if issues persist:
- Review overall Spark job memory configuration
- Consider reducing
spark.openmetadata.transport.timeoutto fail faster
Issue 7: Multiple Pipelines Created for Same Job
Symptoms:
- Each job run creates a new pipeline instead of updating existing one
Solutions:
Use consistent
pipelineName:- Don't use timestamps or random values in pipeline name
- Use the same name across runs
Use consistent
pipelineServiceName:- Ensure service name is the same for all related jobs
Spark Code Patterns That Break Lineage
Certain Spark coding patterns can prevent lineage from being captured correctly. Below are common issues and how to fix them:
Pattern 1: Using Dynamic Table Names
❌ Breaks Lineage:
✅ Fix: Use consistent table names or configure table mapping:
Pattern 2: Creating DataFrames from Local Collections
❌ Breaks Lineage:
✅ Fix: Always read from actual data sources:
Pattern 3: Using RDD Operations
❌ Breaks Lineage:
✅ Fix: Use DataFrame/Dataset APIs:
Pattern 4: Using Temporary Views Without Proper Table References
❌ Breaks Lineage:
✅ Fix: Minimize temp views or use JDBC for output:
Pattern 5: Using collect() and Manual Writes
❌ Breaks Lineage:
✅ Fix: Use Spark's native write operations:
Pattern 6: Using Non-JDBC File Formats Without Catalog
❌ Breaks Lineage:
✅ Fix: Use JDBC sources or register with catalog:
Pattern 7: Mixing Multiple Write Operations
❌ Breaks Lineage:
✅ Fix: Use cache and separate clear operations:
Pattern 8: Using Incorrect JDBC URL Formats
❌ Breaks Lineage:
✅ Fix: Use proper JDBC URLs and table names:
Pattern 9: Using saveAsTable Without Database Prefix
❌ Breaks Lineage:
✅ Fix: Specify database explicitly:
Pattern 10: Schema Mismatches Between Spark and OpenMetadata
❌ Breaks Lineage:
✅ Fix: Match table names exactly as in OpenMetadata:
Pattern 11: Using Deprecated Write APIs
❌ Breaks Lineage:
✅ Fix: Use modern DataFrame write API:
Pattern 12: Not Specifying Driver Class
❌ Breaks Lineage:
✅ Fix: Always specify driver:
Best Practices for Lineage-Friendly Spark Code
Always use JDBC format explicitly:
Use fully qualified table names:
Avoid dynamic table names - use static names:
Prefer DataFrame API over SQL strings:
Always specify database in JDBC URL:
Use consistent naming across Spark and OpenMetadata:
- Check table names in OpenMetadata UI
- Match exact casing and schema names
Avoid intermediate local collections:
Test lineage with simple job first:
Debug Mode
Enable debug logging for detailed troubleshooting:
This will output detailed logs about:
- Lineage events being captured
- API calls to OpenMetadata
- Table resolution process
- Error details
- Which tables/operations are detected
Getting Help
If you're still experiencing issues:
- Check Spark logs with debug mode enabled
- Check OpenMetadata server logs:
/opt/openmetadata/logs/ - Verify network connectivity between Spark and OpenMetadata
- Check OpenMetadata version compatibility
- Review OpenMetadata Spark Agent GitHub issues: https://github.com/open-metadata/openmetadata-spark-agent/issues
- Join OpenMetadata Slack community for support
Diagnostic Checklist
When reporting issues, please provide:
- [ ] Spark version
- [ ] OpenMetadata version
- [ ] OpenMetadata Spark Agent version
- [ ] Deployment platform (YARN/Kubernetes/Standalone/Local)
- [ ] Spark job logs (with debug mode enabled)
- [ ] OpenMetadata server logs
- [ ] Network test results (curl to OpenMetadata API)
- [ ] Configuration used (with sensitive values redacted)