How do the Upgrade & Backup work?
If this is the first time you are trying to upgrade OpenMetadata, or you just have some doubts on how the backup and upgrade process work, this is the place to be. We will cover:
- What is being backed up?
- When should we restore?
- What happens during the migration?
Architecture Review
Let's start with a simplified design review of OpenMetadata. You can find further details here, but we'll now focus on the Server & the Database:

All the metadata is stored in a MySQL or Postgres instance. The shape of the data is managed using Flyway, and the migration scripts are handled here.
In a nutshell, we have a data model in which we store all of this information. The definition of this model (table names, schemas,...) is managed using Flyway migrations. In every release, the structure of this data model can change. This means that the shape of the database is tightly coupled to your OpenMetadata Server version.
1. What is being backed up?
You can find all the necessary information on how to run the backups here.
When we backup the data, we are creating an SQL file that follows the shape of the database of a specific version. Thus, if we have some issues on our instance, and we ever need to restore that data, it will only fit to a database with that same version shape.
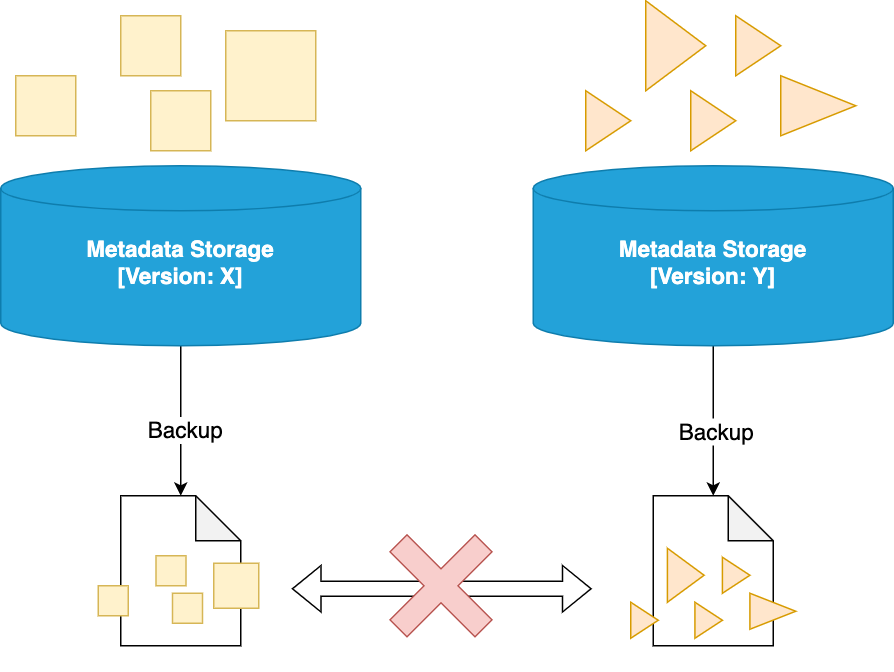
2. When should we restore?
Now that we understand what is being backed up and how it looks like, when (and where) should we restore?
- When: We restore the data if we need to get back in time. Restoring is never needed during the upgrade process.
- Where: We will restore the data to a clean database with the Flyway migrations at the same version as the backed up data. The usual process will be:
Note that the restore process will not work if we try to restore some data taken from version X to a database shaped with version Y.
3. What happens during the migration?
We have been explaining how each OpenMetadata Server relies on a specific data model to store the metadata. What happens when we upgrade from version X to Y?
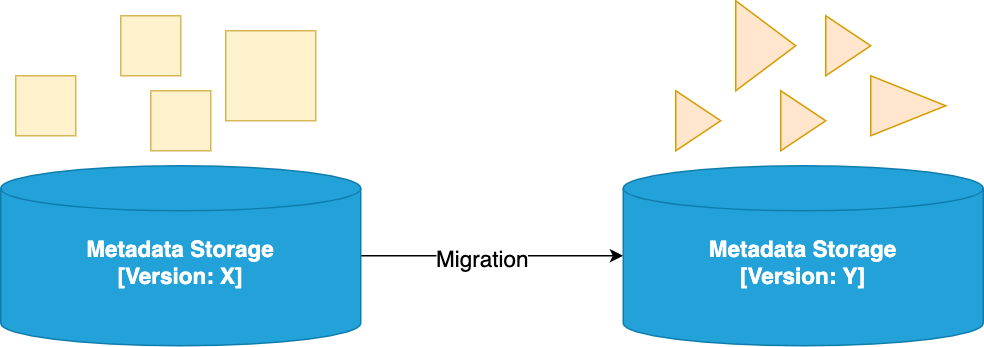
The migration process will take care of getting the data shaped as X and transform it to the Y shape. After the migration is done, the server in version Y will be able to run properly.