Connector Troubleshooting Guide
This guide provides instructions to help resolve common issues encountered during connector setup and metadata ingestion in OpenMetadata. Below are some of the most frequently observed troubleshooting scenarios.
- ADLS Datalake
- AzureSQL
- Databricks
- Domo Database
- Hive
- Impala
- MSSQL
- PostgreSQL
- Redshift
- S3 Datalake
- Vertica
- Kafka
- Nifi
How to Enable Debug Logging for Any Ingestion
To enable debug logging for any ingestion workflow in OpenMetadata:
Navigate to Services Go to Settings > Services > Service Type (e.g., Database) in the OpenMetadata UI.
Select a Service Choose the specific service for which you want to enable debug logging.
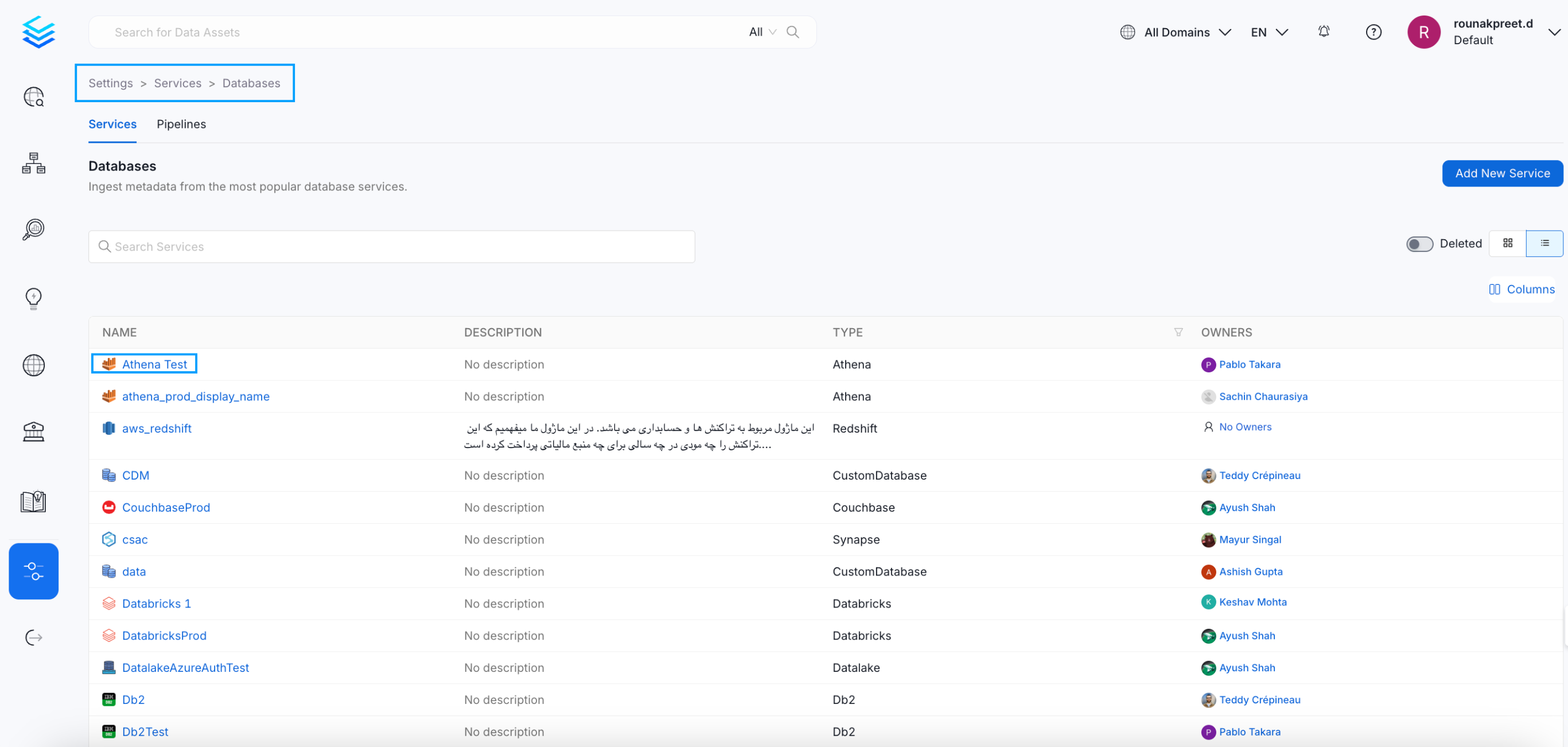
Select a Service
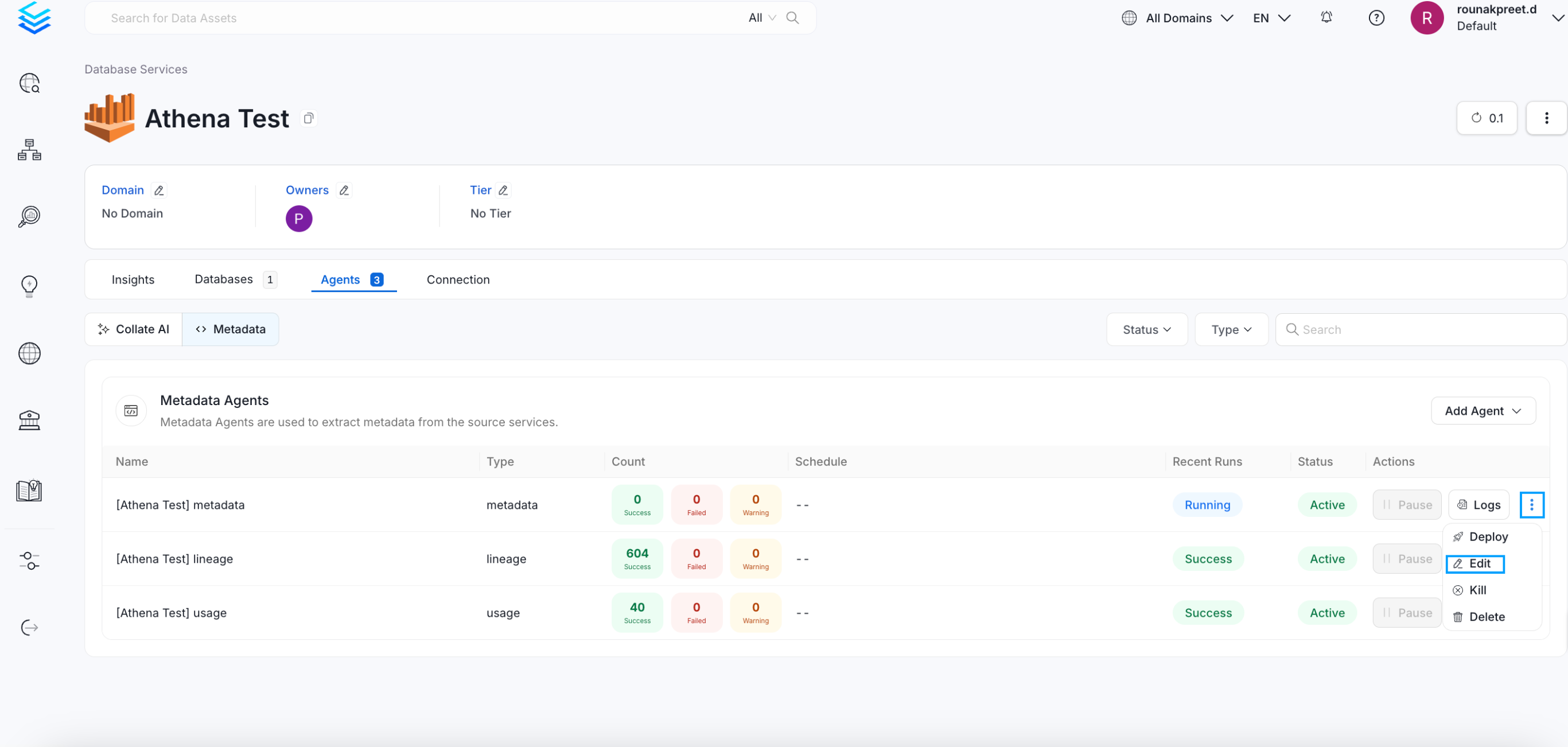
- Access Ingestion Tab Go to the Ingestion tab and click the three-dot menu on the right-hand side of the ingestion type, and select Edit.
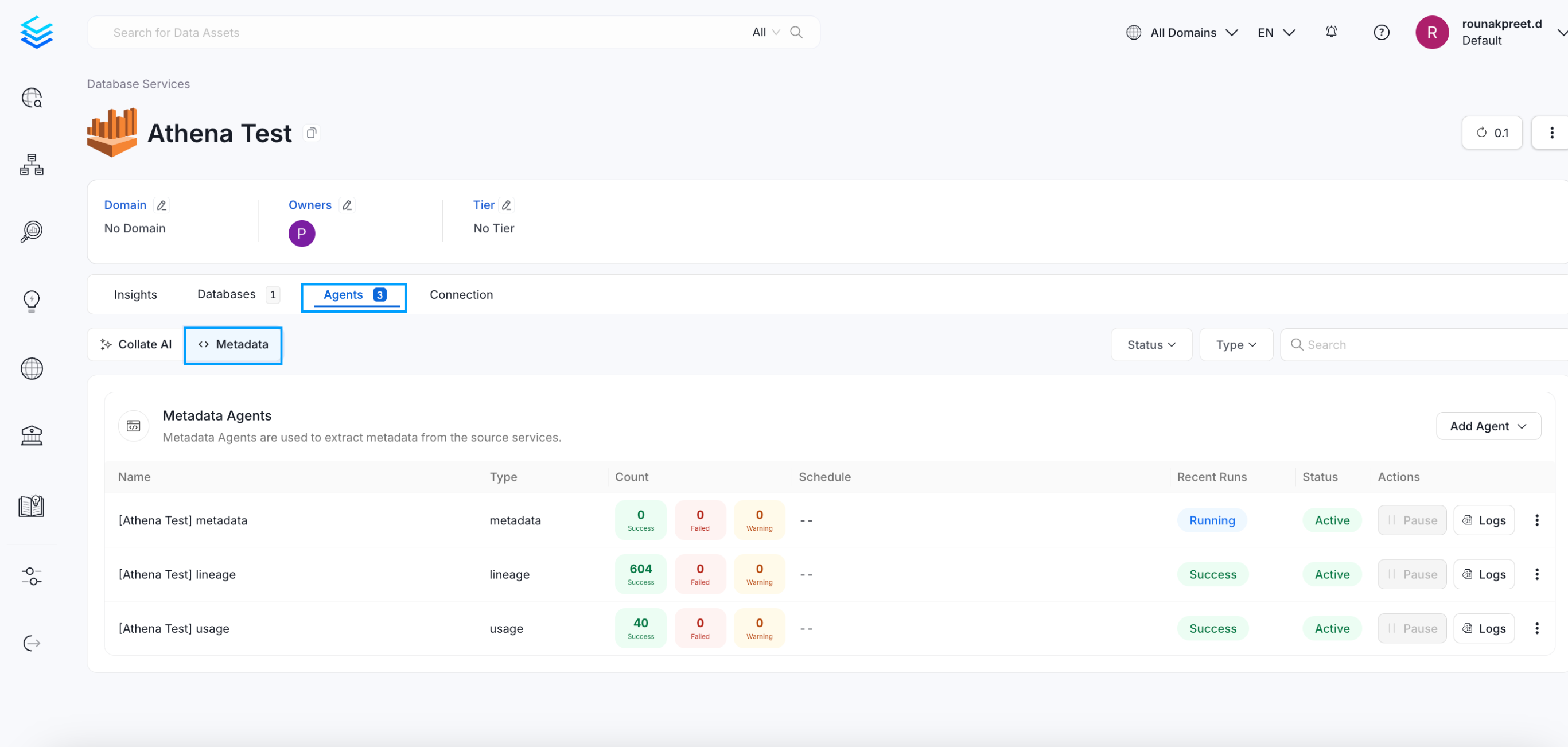
Access Agents Tab
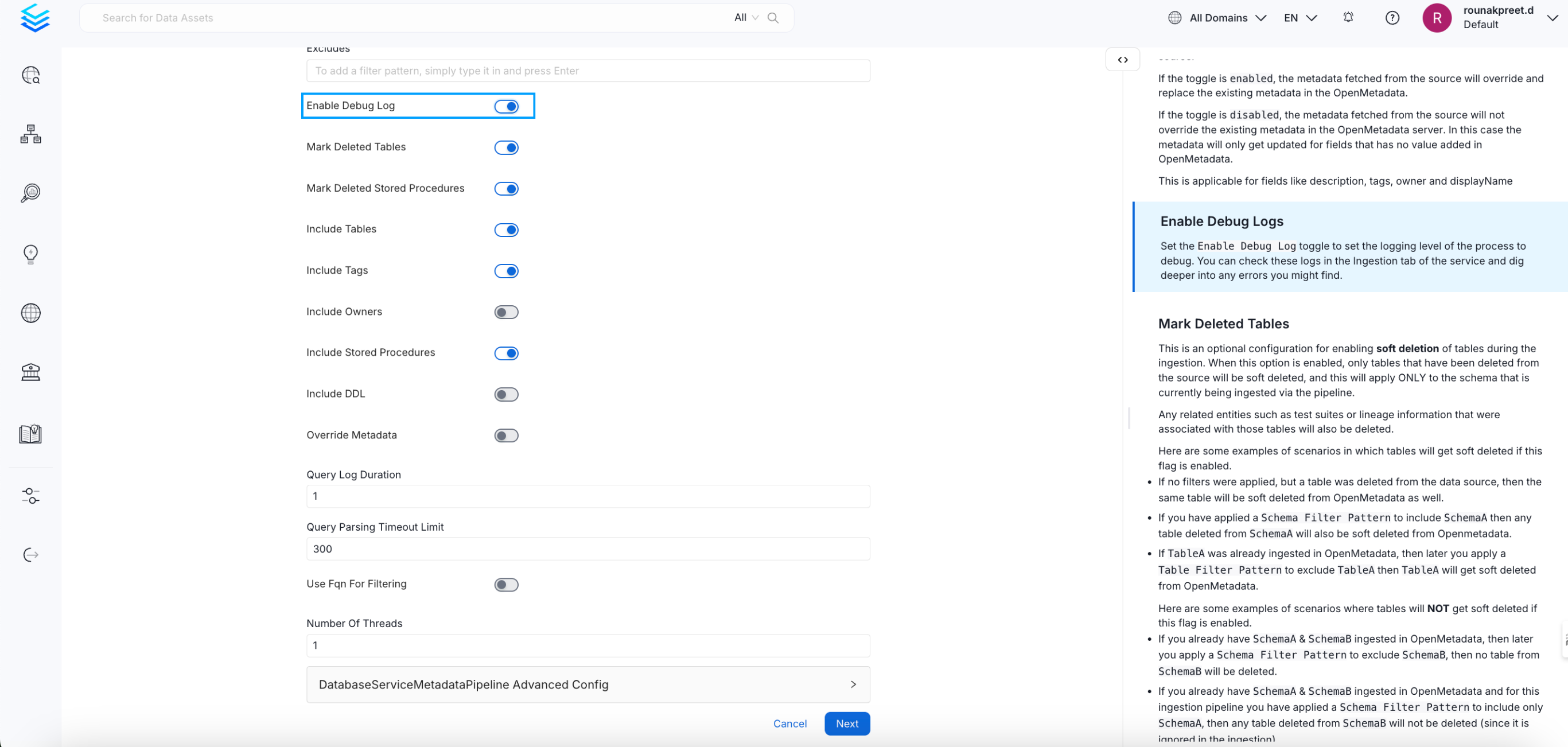
- Enable Debug Logging In the configuration dialog, enable the Debug Log option and click Next.
Enable Debug Logging
- Schedule and Submit Configure the schedule if needed and click Submit to apply the changes.
Schedule and Submit
Permission Issues
If you encounter permission-related errors during connector setup or metadata ingestion, ensure that all the prerequisites and access configurations specified for each connector are properly implemented. Refer to the connector-specific documentation to verify the required permissions.
ADLS Datalake
Learn how to resolve the most common problems people encounter in the ADLS Datalake connector.
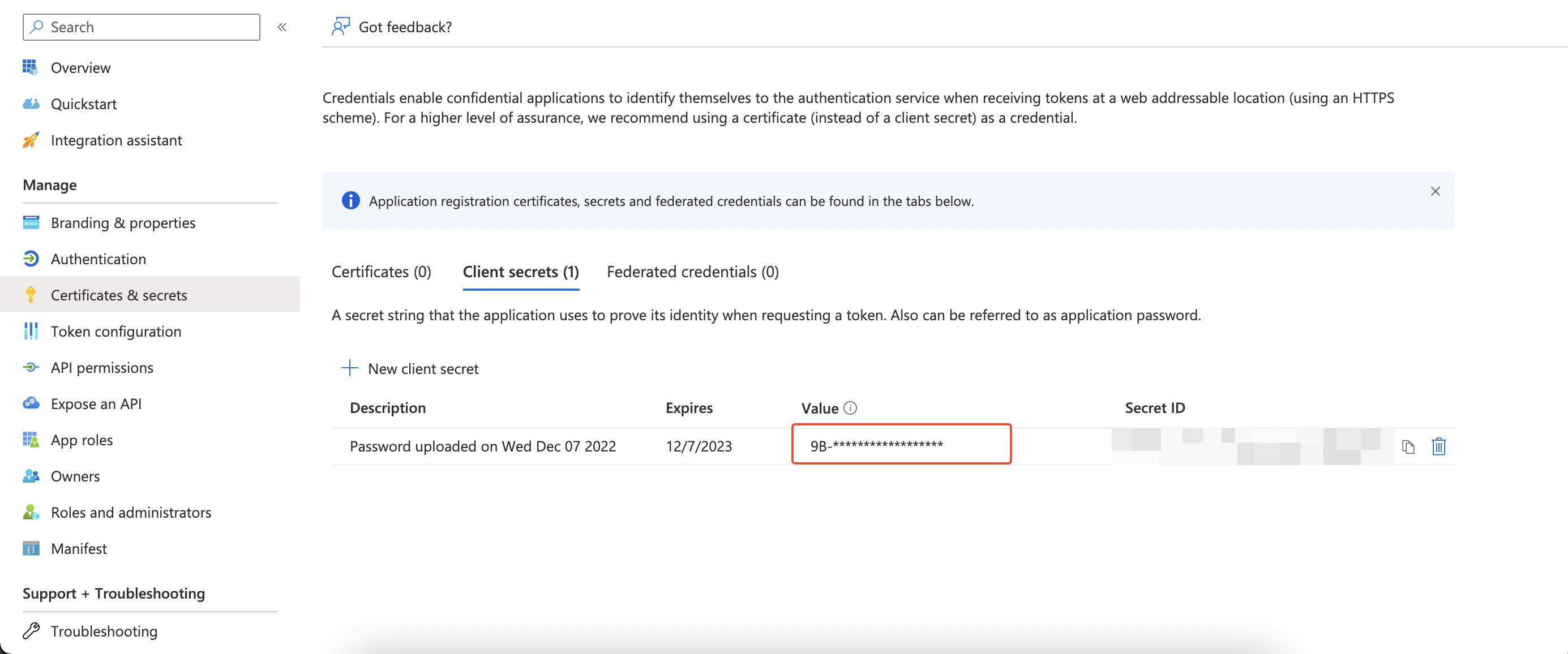
'Azure Datalake' credentials details
Where can I find 'Client Secret' from.
- Login to
Azure Portal - Find and click on your application
- Select
Certificates & SecretunderManageSection
Find Client ID
AzureSQL
Learn how to resolve the most common problems people encounter in the AzureSQL connector.
- Unknown error connecting with Engine [...]; An attempt to complete a transaction has failed. No corresponding transaction found. (111214) (SQLEndTran)
This is an exception you can get when trying to connect to AzureSQL using SQLAlchemy (the internal OpenMetadata Ingestion library for reaching databases).
To solve this issue, you can edit your Service Connection by adding the following Connection Argument:
- Key:
autocommit - Value:
true

- Cannot open server '[server name]' requested by the login. Client with IP address '[your IP]' is not allowed to access the server
This is an exception you can get when trying to connect to AzureSQL using SQLAlchemy (the internal OpenMetadata Ingestion library for reaching databases).
To solve this issue, you need to add your IP address in firewall rules for your Azure SQL instance.
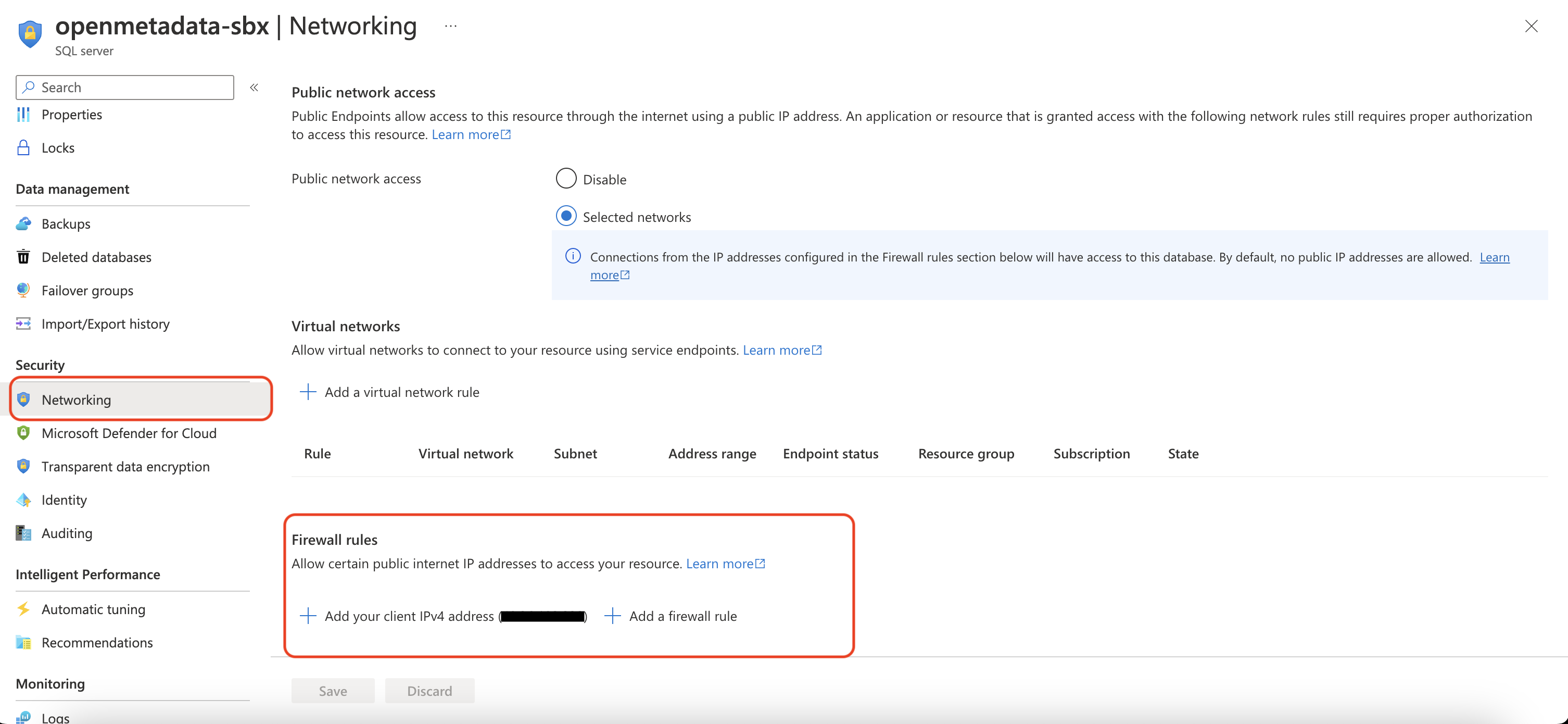
azure sql firewall rules
Databricks
Databricks connection details
Here are the steps to get hostPort, token and http_path.
First login to Azure Databricks and from side bar select SQL Warehouse (In SQL section)
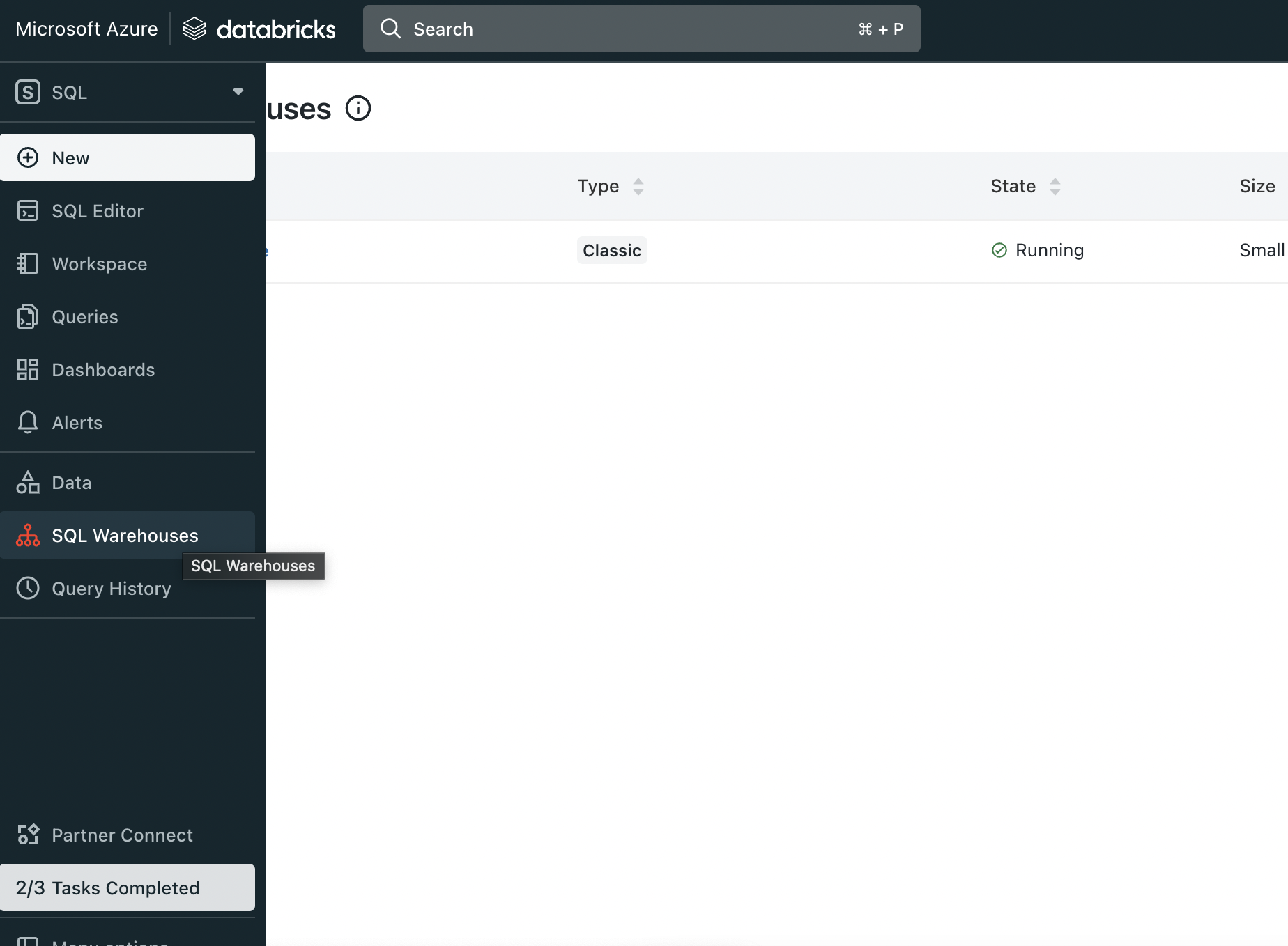
Select Sql Warehouse
Now click on sql Warehouse from the SQL Warehouses list.
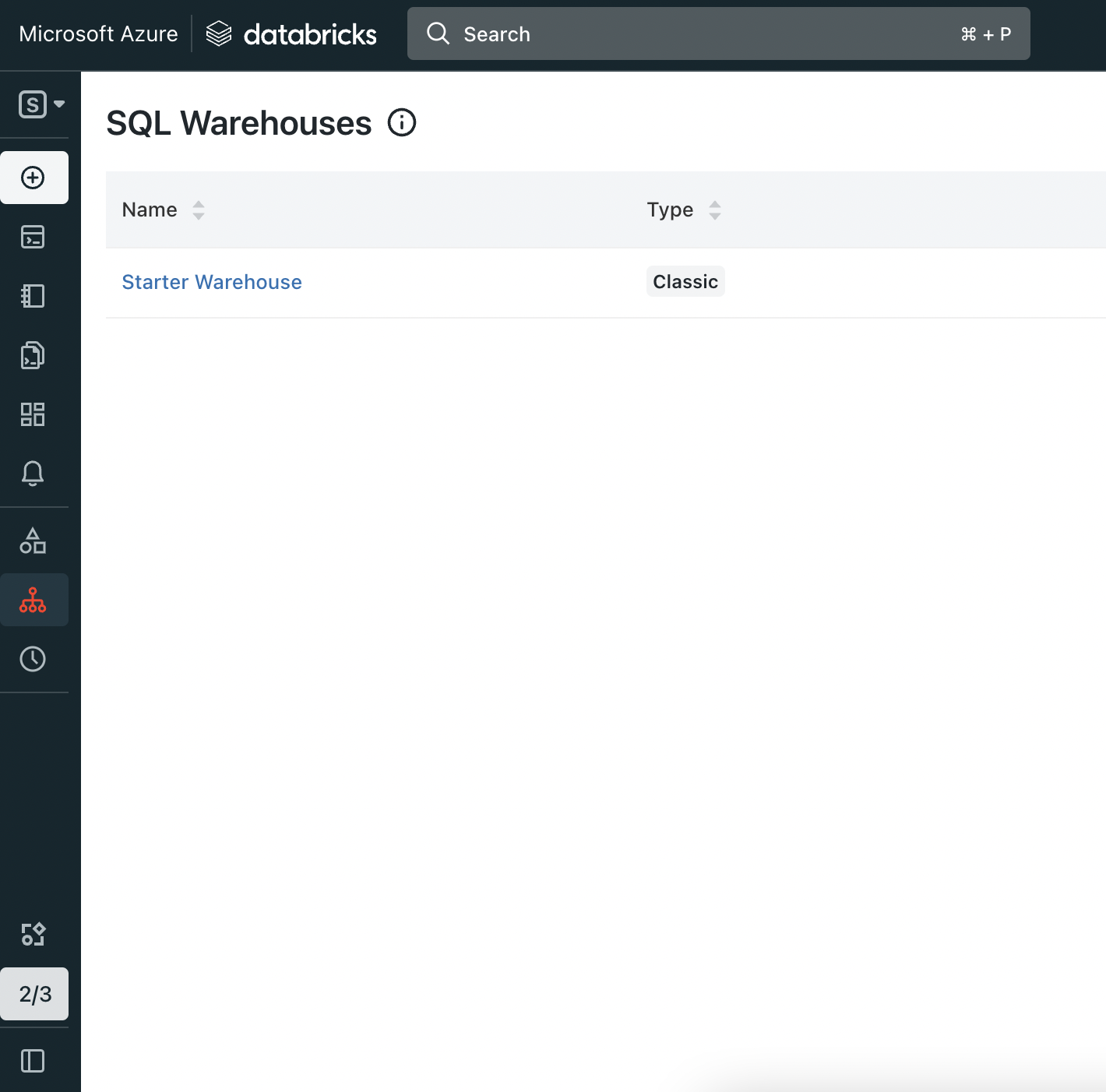
Open Sql Warehouse
Now inside that page go to Connection details section. In this page Server hostname and Port is your hostPort, HTTP path is your http_path.
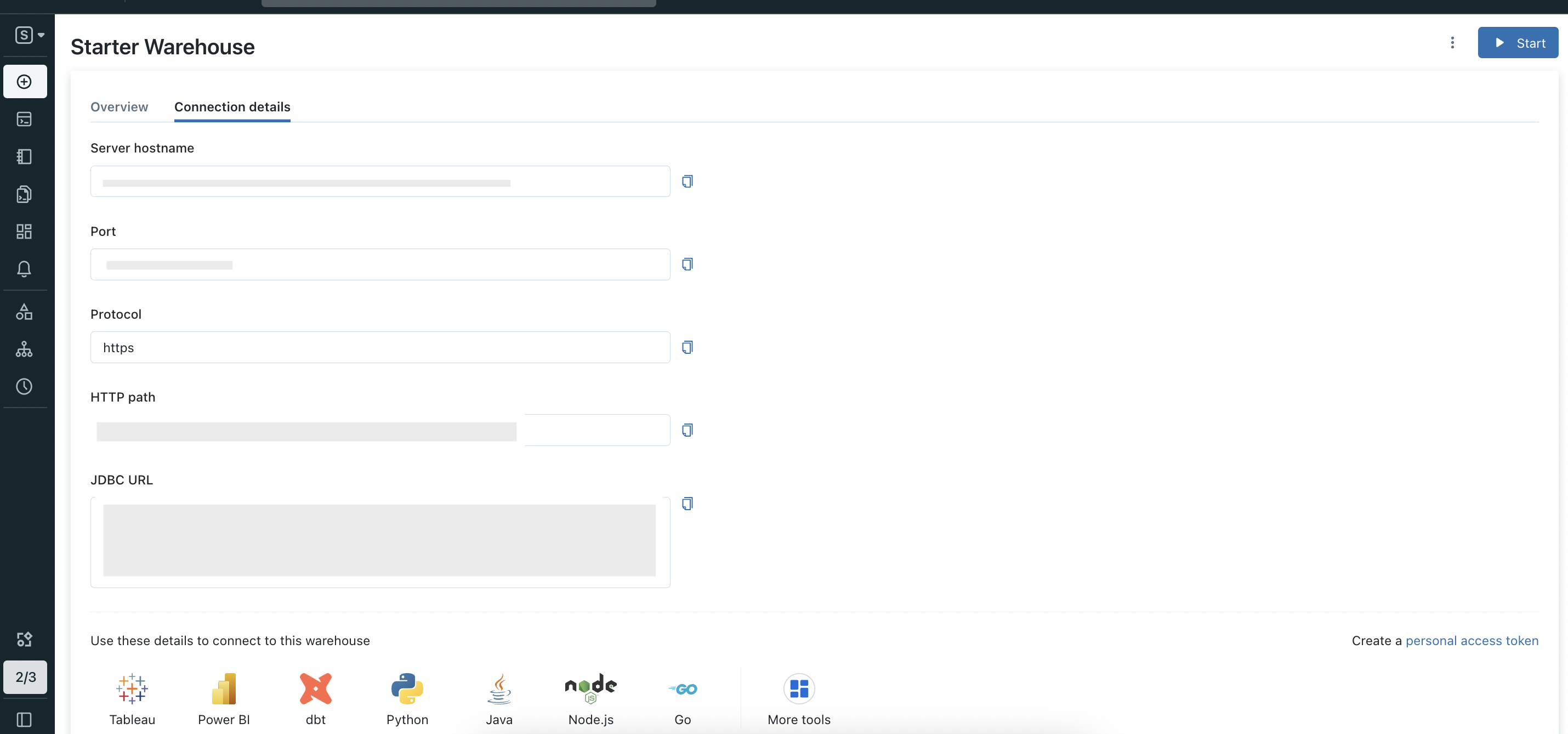
Connection details
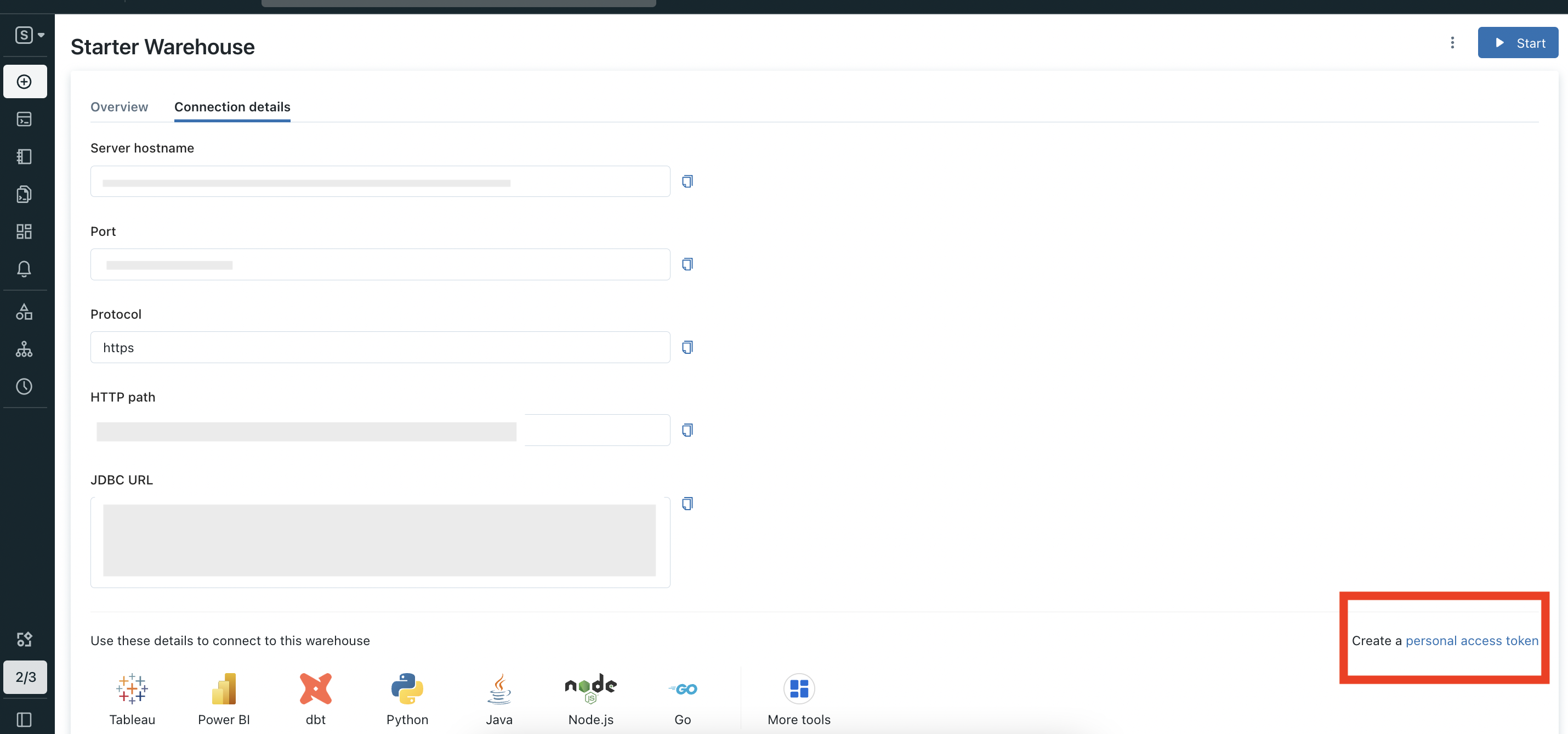
In Connection details section page click on Create a personal access token.

Open create token
Now In this page you can create new token.
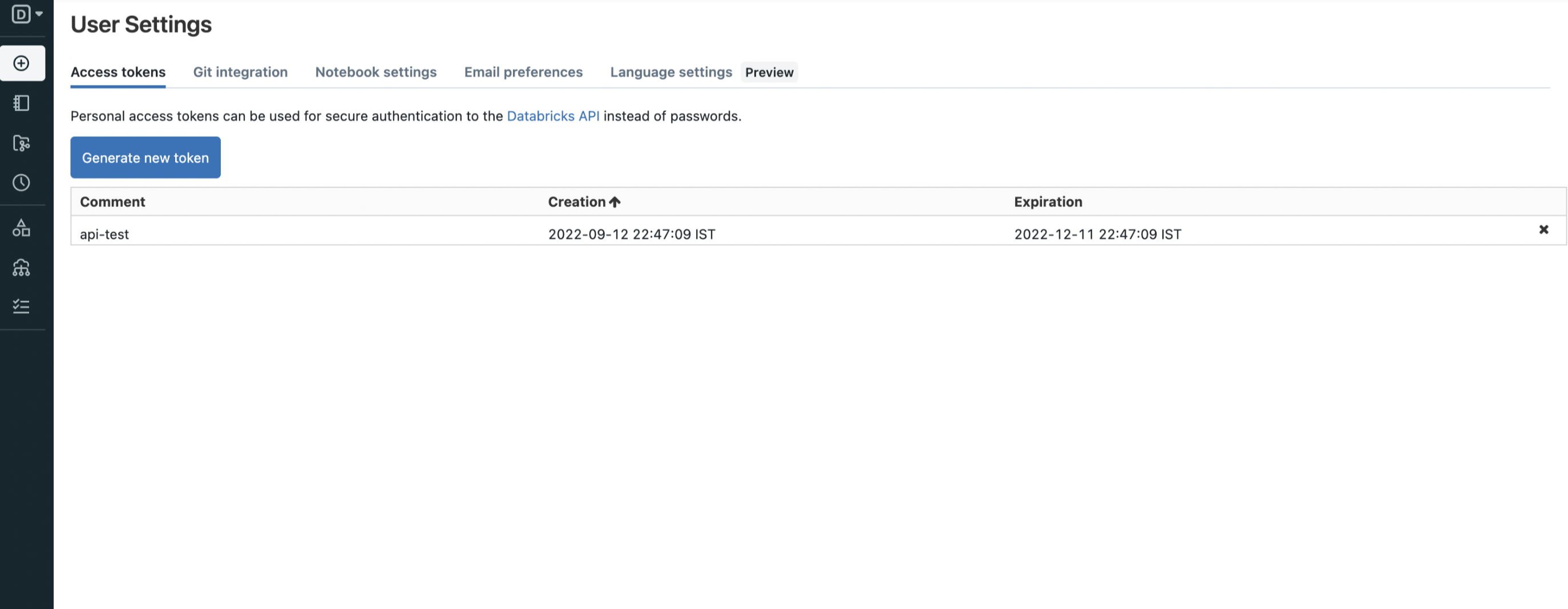
Generate token
Domo Database
Learn how to resolve the most common problems people encounter in the Domo Database connector.
How to find clientId?
- You can find your
clientIdby logging into your domo instance. - After that click on
My Account>Manage Clients(if created).
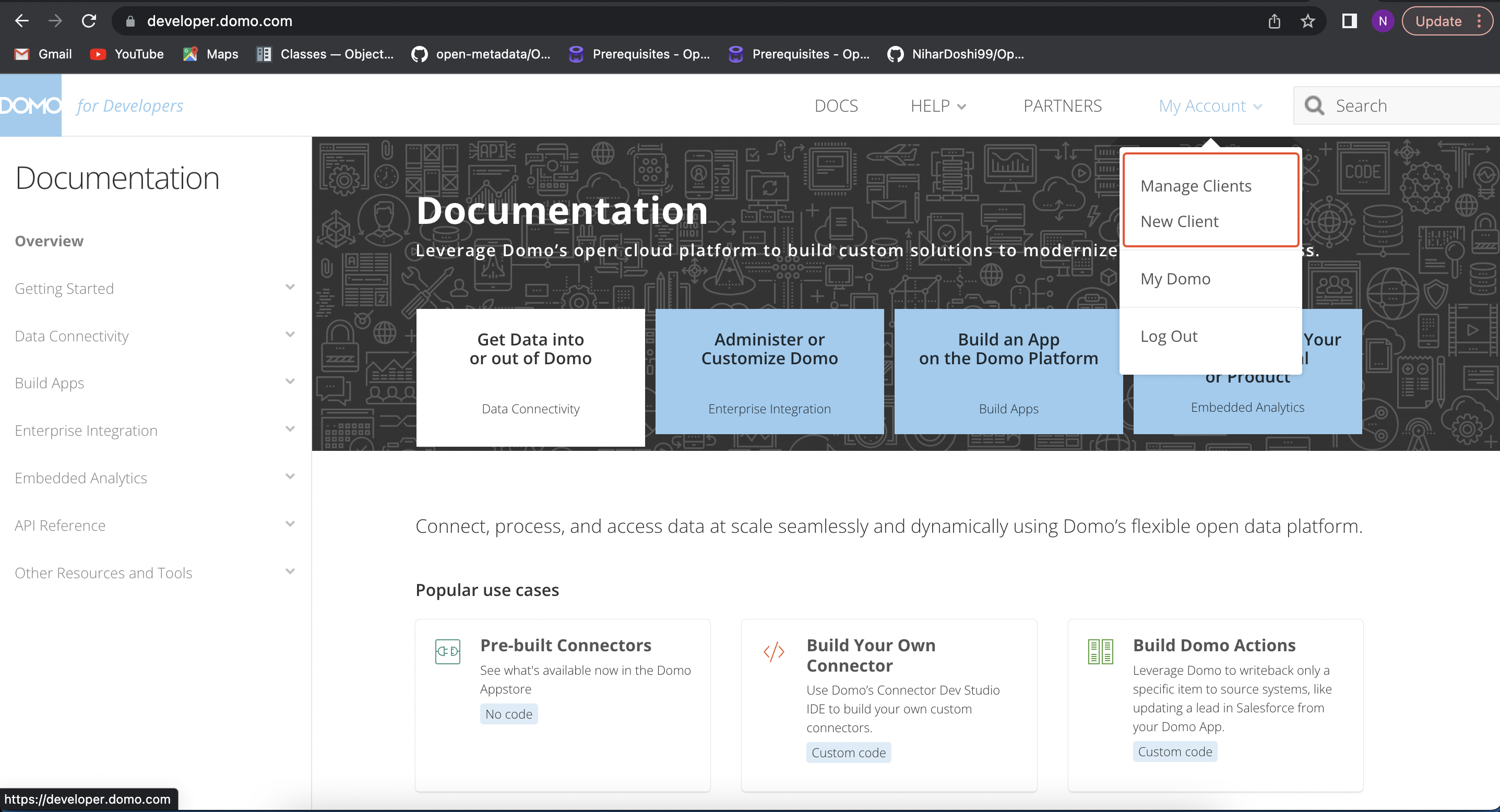
Find Services under the Settings menu
Where to find accessToken?
- You need to generate accessToken.
- Login into your sandbox domain ex.
<your-domain>.domo.com. - Click on the
MOREbutton on navbar, after that click onAdmin. - Under
Authenticationyou will findAccess tokens.
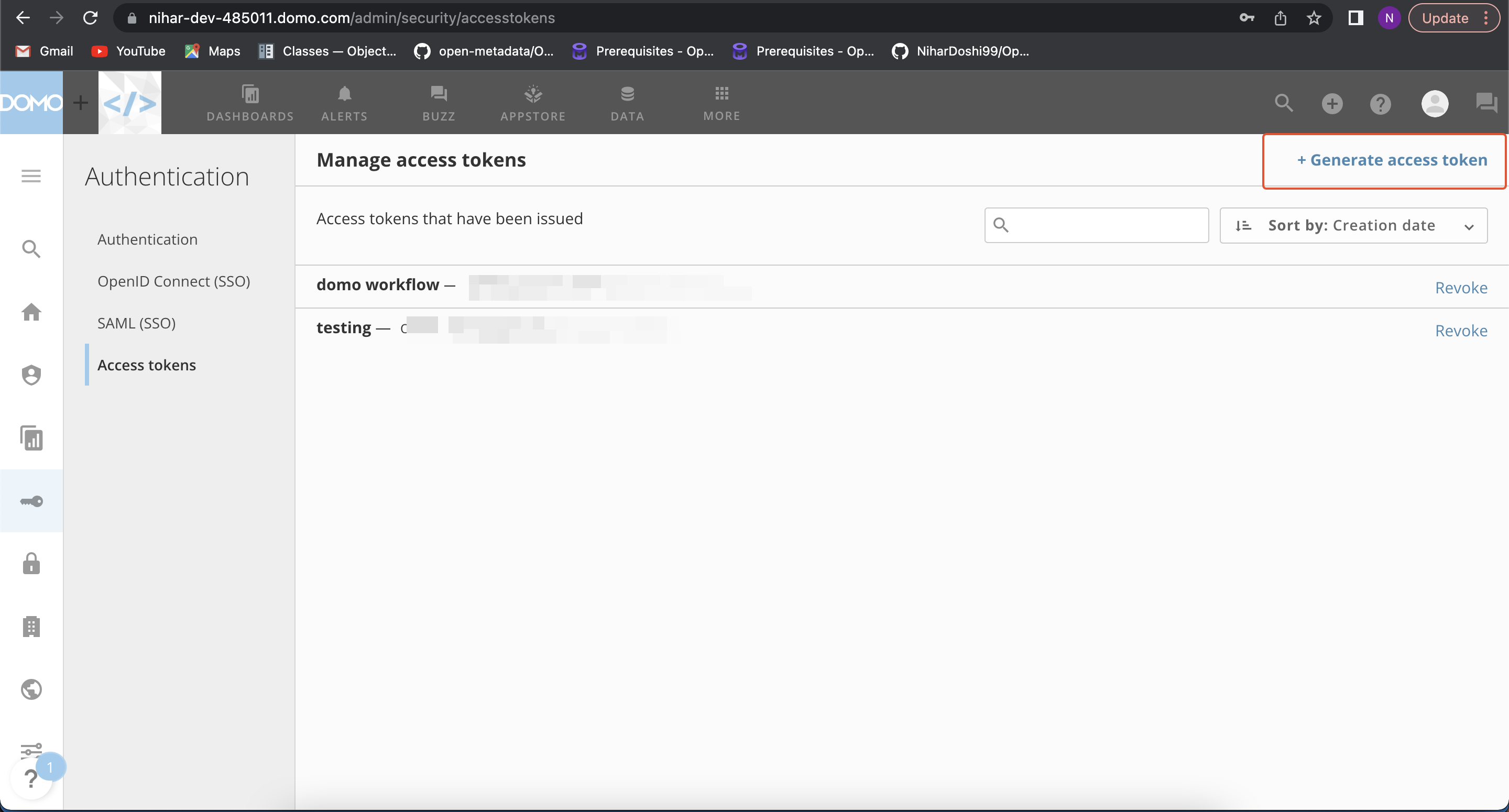
access-token
Where can I find my scopes?
- Scopes can be find Under
Manage Clientssection inMy Account(If client not found, click here)
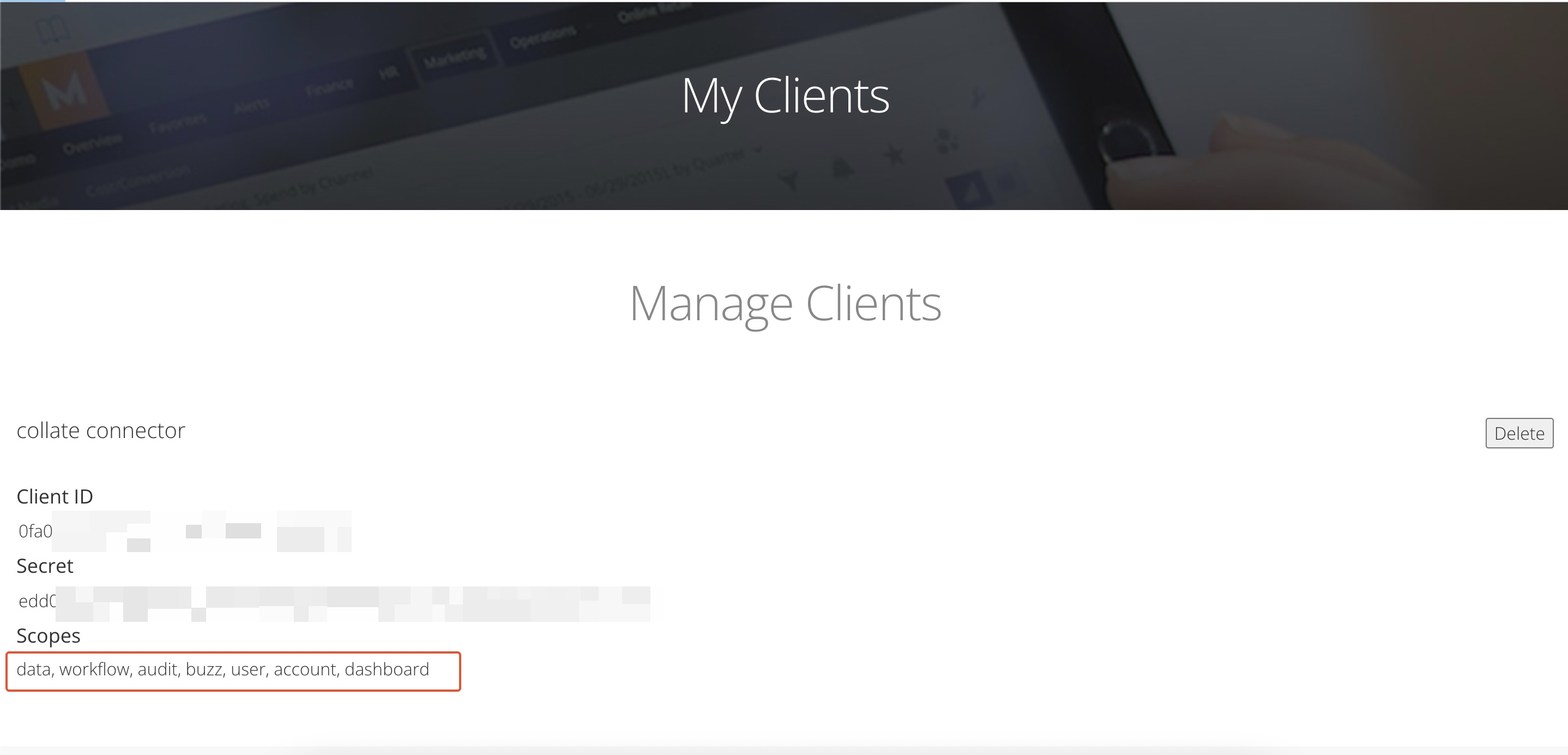
Scopes
Hive
Learn how to resolve the most common problems people encounter in the Hive connector.
Connection Timeout
You might be getting thrift.transport.TTransport.TTransportException: TSocket read 0 bytes.
Make sure that if there is a Load Balancer in between OpenMetadata and Hive, the LB timeout is not impacting the ingestion. For example, when extracting data with a lot of partitions the DESCRIBE command might take more than 60 seconds, so a Load Balancer with Idle Timeout at 60 seconds would kill the connection.
Impala
Learn how to resolve the most common problems people encounter in the Impala connector.
Connection Timeout
You might be getting thrift.transport.TTransport.TTransportException: TSocket read 0 bytes.
Make sure that if there is a Load Balancer in between OpenMetadata and Impala, the LB timeout is not impacting the ingestion. For example, when extracting data with a lot of partitions the DESCRIBE command might take more than 60 seconds, so a Load Balancer with Idle Timeout at 60 seconds would kill the connection.
MSSQL
Resolving SQL Server Authentication Issue for Windows User
This guide addresses a common issue when connecting to a SQL Server instance using Windows OS. If you encounter the error below, follow the steps outlined to resolve it effectively.
Error Description
When attempting to connect to SQL Server using a Windows user, the following error appears:
Additionally, the SQL Server logs display:
Root Cause
The error occurs because the connection is configured to use SQL Server Authentication instead of Windows Authentication. Windows Authentication requires a connection scheme that supports integrated security.
Resolution
Step 1: Verify Connection Configuration
- Ensure that you are connecting to SQL Server using Windows Authentication.
- Update the connection scheme to use
mssql+pymssqlinstead ofmssql.pyodbc.
Step 2: Update the Connection Details in Collate
- Navigate to MSSQL Service Configuration in the Collate UI.
- Update the Connection Scheme to
mssql+pymssql. - Retain the following connection details:
- Host and Port: e.g.,
10.121.89.148:62452. - Database: Specify the target database (e.g.,
OneSumx_Stoging). - Username: Use the Windows account username, e.g.,
domain\user.
- Host and Port: e.g.,
- Save the updated configuration.
Step 3: Test the Connection
- After saving the changes, click Test Connection in the Collate UI.
- Confirm that the following steps pass successfully:
- CheckAccess
- GetDatabases
- GetSchemas
- GetTables
- GetViews
- GetQueries
Expected Outcome
After updating the connection scheme, the connection should succeed. The status will display:
PostgreSQL
Learn how to resolve the most common problems people encounter in the PostgreSQL connector.
Column XYZ does not exist
If when running the metadata ingestion workflow you get a similar error to:
Then you might be using an unsupported postgres version. If we double-check the requirements for the postgres connector: Note that we only support officially supported PostgreSQL versions. You can check the version list here.
Error: no pg_hba.conf entry for host
When trying to connect to a PostgreSQL server hosted on Azure/AWS using basic authentication, the connection may fail with the following error message:
This error generally indicates that the host trying to access the PostgreSQL server is not permitted according to the server's pg_hba.conf configuration, which manages authentication.
Whitelist the IP address
Ensure that the IP address provided by the OpenMetadata Service wizard is whitelisted in the Azure network firewall rules. You should also verify that the correct IP is added in the firewall for the database to allow connections from OpenMetadata.Check pg_hba.conf File
While Azure-managed PostgreSQL doesn't allow direct access to modify thepg_hba.conffile, you can control access using Azure Firewall rules. Ensure that the IP address attempting to connect is allowed.Verify Network Access
Ensure that the PostgreSQL server is accessible from the internet for the allowed IP addresses. If the server is behind a VPN or private network, adjust the network settings accordingly.Adjust SSL Mode
The error could also be related to SSL settings. Setting the SSL mode toallowcan help resolve this issue. Modify the connection settings in the OpenMetadata Service configuration to:
This will allow the connection even if SSL is not enforced by the server.
Redshift
Learn how to resolve the most common problems people encounter in the Redshift connector.
Connection Error
If you get this error that time please pass {'sslmode': 'verify-ca'} in the connection arguments.
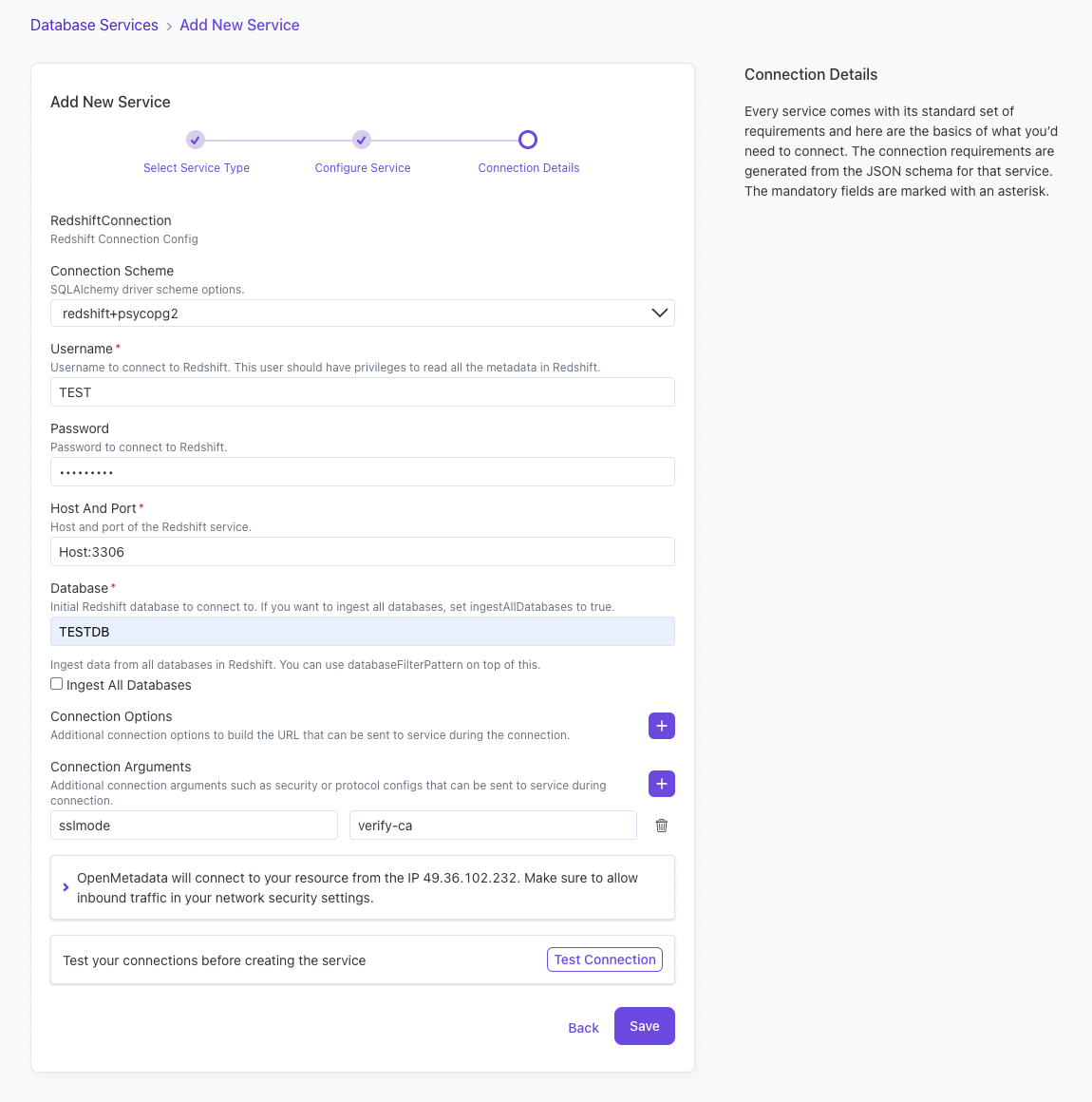
Configure the service connection by filling the form
Metadata Ingestion Failure
If your metadata ingesiton fails and you have errors like:
This is because the schema information_schema is being ingested and the ingestion bot does not have the permissions to access it. It is recommended to exclude the schema information_schema unless you explicitly need to ingest it like in the example config.
S3 Datalake
Learn how to resolve the most common problems people encounter in the S3 Datalake connector.
- 'Access Denied' error when reading from S3 bucket
Please, ensure you have a Bucket Policy with the permissions explained in the requirement section here.
Unity Catalog
Unity Catalog connection details
Here are the steps to get hostPort, token and http_path.
First login to Azure Databricks and from side bar select SQL Warehouse (In SQL section)
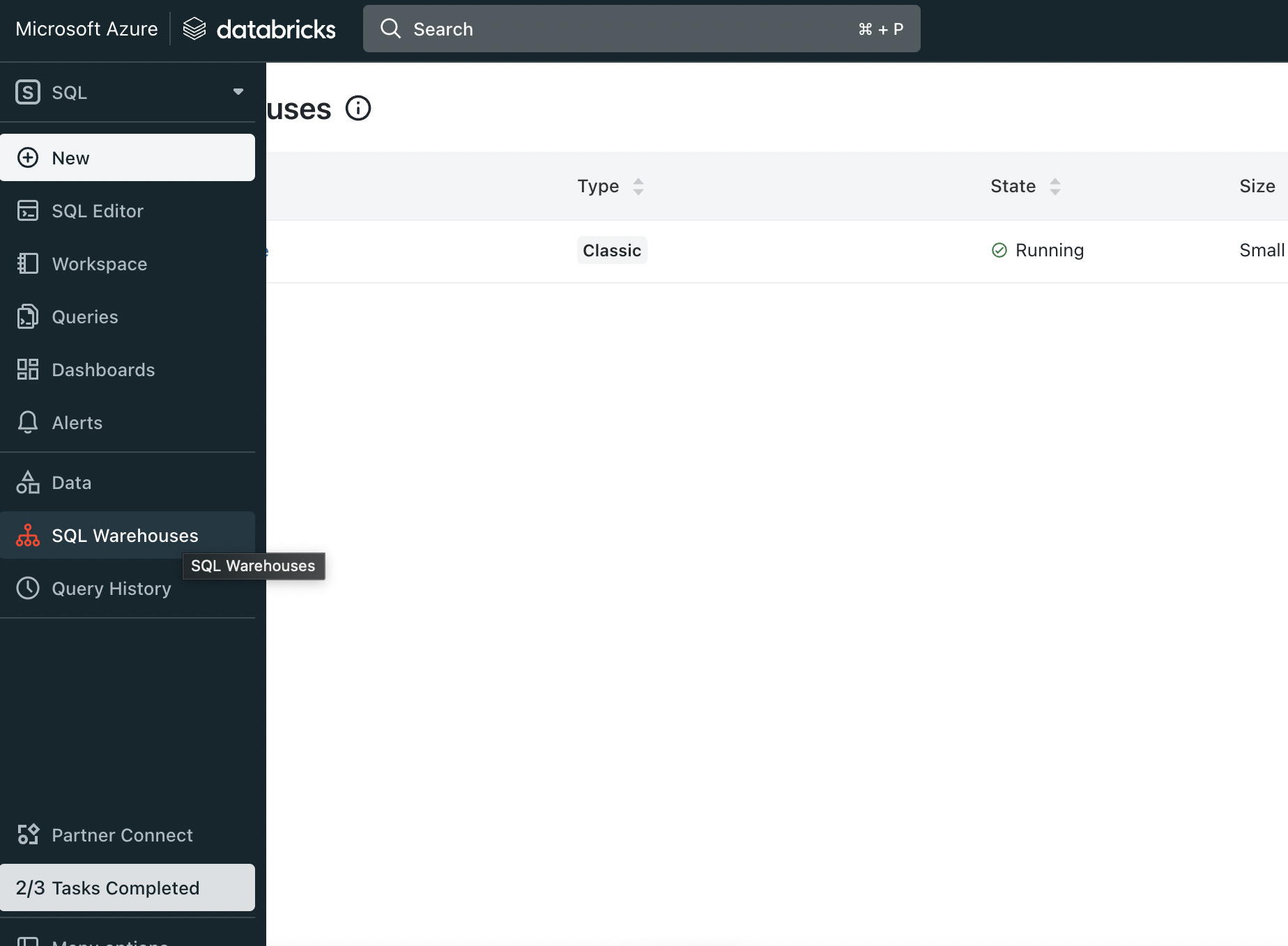
Select Sql Warehouse
Now click on sql Warehouse from the SQL Warehouses list.
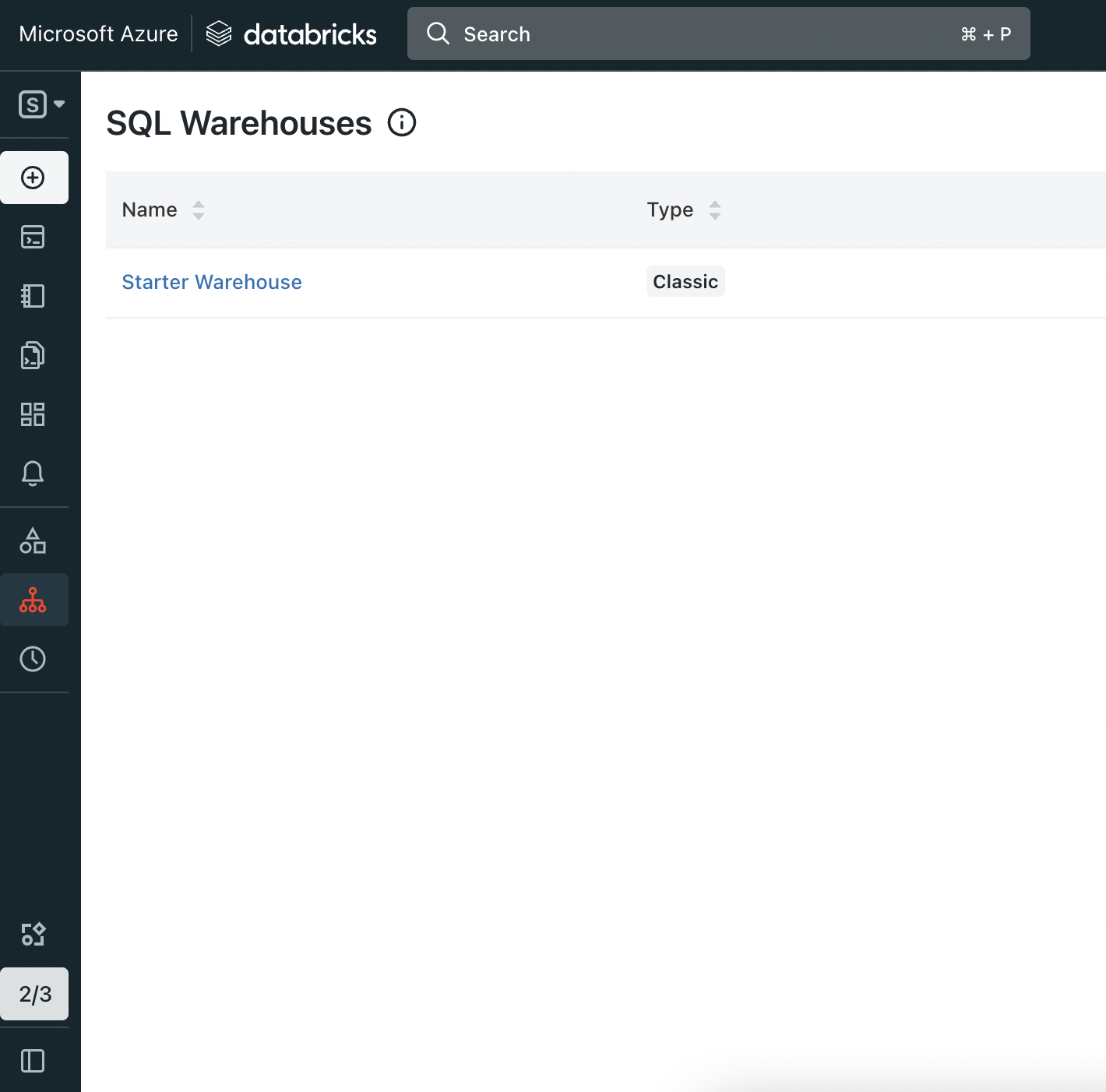
Open Sql Warehouse
Now inside that page go to Connection details section. In this page Server hostname and Port is your hostPort, HTTP path is your http_path.
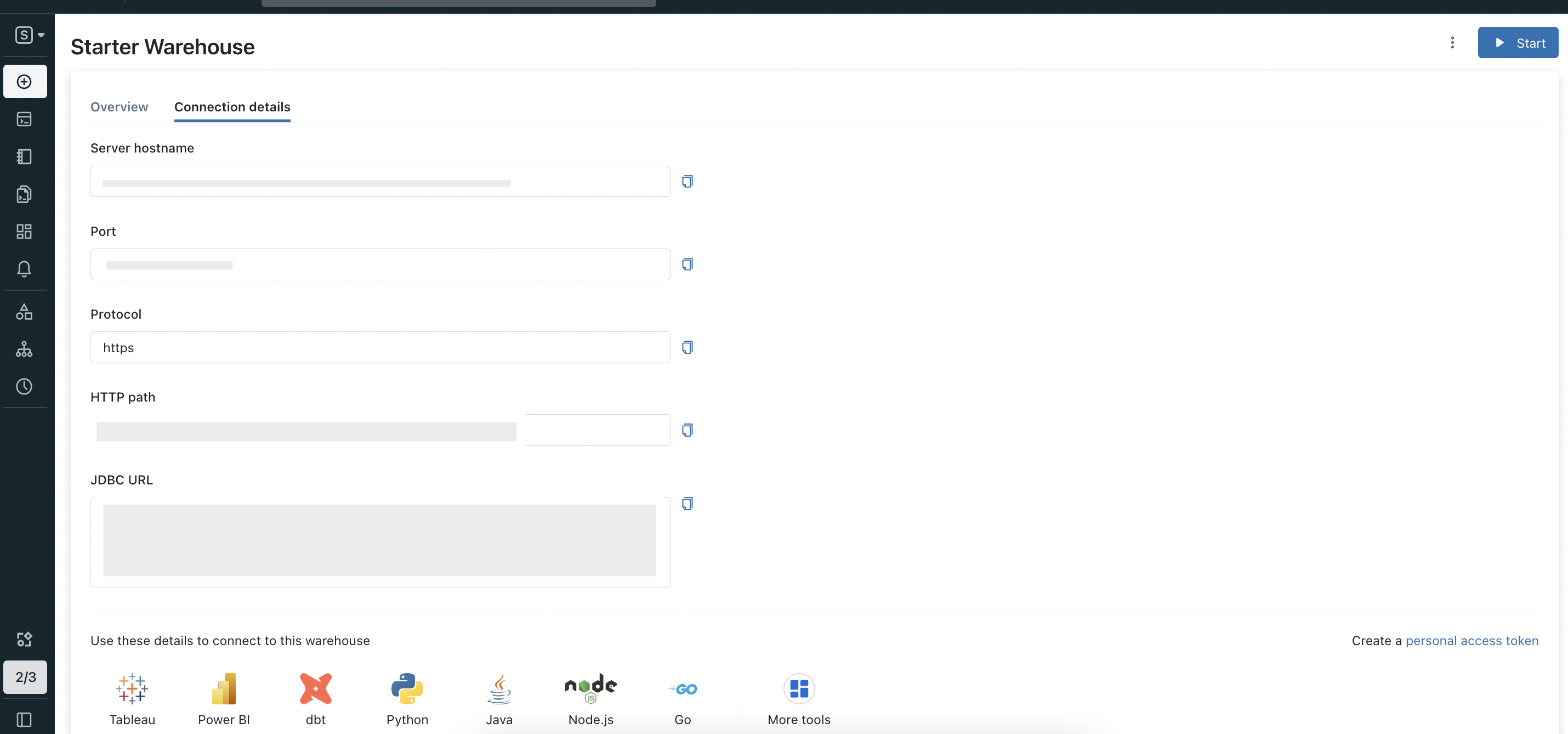
Connection details
In Connection details section page click on Create a personal access token.
Open create token
Now In this page you can create new token.
Generate token
Vertica
Learn how to resolve the most common problems people encounter in the Vertica connector.
Profiler: New session rejected
If you see the following error when computing the profiler New session rejected due to limit, already XYZ sessions active, it means that the number of threads configured in the profiler workflow is exceeding the connection limits of your Vertica instance.
Note that by default the profiler runs with 5 threads. In case you see this error, you might need to reduce this number.
Kafka
Consumer and schema registry config
When configuring the Kafka connector, we could need to pass extra parameters to the consumer or the schema registry to be able to connect. The accepted values for the consumer can be found in the following link, while the ones optional for the schema registry are here.
If you encounter issues connecting to the Schema Registry, ensure that the protocol is explicitly specified in the Schema Registry URL. For example:
- Use
http://localhost:8081instead oflocalhost:8081. The Schema Registry requires a properly formatted URL, including the protocol (http://orhttps://). While this differentiation is expected in the Schema Registry configuration, it may not be immediately apparent.
In case you are performing the ingestion through the CLI with a YAML file, the service connection config should look like this:
Connecting to Confluent Cloud Kafka
If you are using Confluent kafka and SSL encryption is enabled you need to add security.protocol as key and SASL_SSL as value under Consumer Config
Nifi
Learn how to resolve the most common problems people encounter in the Nifi connector.
No applicable policies could be found
If you see the error No applicable policies could be found. Contact the system administrator during the Test Connection or when running the ingestion, you will need to add the missing policies in the Nifi instance.
You can find more information in this link.
The accepted answer is to add a policy to authorizations.xml as follows: